S08-01 Node-基础、模块化、包管理工具、事件循环
[TOC]
概述
Atwood 定律
Atwood 定律: 任何可以使用 JavaScript 来实现的应用都最终都会使用 JavaScript 实现。
Stack Overflow 的创立者之一的 Jeff Atwood 在 2007 年提出了著名的 Atwood 定律:
- Any application that can be written in JavaScript, will eventually be written in JavaScript.
- 任何可以使用 JavaScript 来实现的应用都最终都会使用 JavaScript 实现。
但是在发明之初,JavaScript 的目的是应用于在浏览器执行简单的脚本任务,对浏览器以及其中的 DOM 进行各种操作,所以 JavaScript 的应用场景非常受限。
- Atwood 定律更像是一种美好的远景,在当时看来还没有实现的可能性。
- 但是随着 Node 的出现,Atwood 定律已经越来越多的被证实是正确的。
但是为了可以理解 Node.js 到底是如何帮助我们做到这一点的,我们必须了解 JavaScript 是如何被运行的。
浏览器内核
浏览器内核: 又名排版引擎(layout engine),也称为浏览器引擎(browser engine)、页面渲染引擎(rendering engine)或样版引擎。
浏览器内核-分类:
- Gecko:早期被 Netscape 和 Mozilla Firefox 浏览器浏览器使用;
- Trident:微软开发,被 IE4~IE11 浏览器使用,但是 Edge 浏览器已经转向 Blink;
- Webkit:苹果基于 KHTML 开发、开源的,用于 Safari,Google Chrome 之前也在使用;
- Blink:是 Webkit 的一个分支,Google 开发,目前应用于 Google Chrome、Edge、Opera 等;
浏览器内核-组成:
- WebCore:负责 HTML 解析、布局、渲染等等相关的工作;
- JavaScriptCore:解析、执行 JavaScript 代码;
小程序中编写的 JavaScript 代码就是被 JSCore 执行的
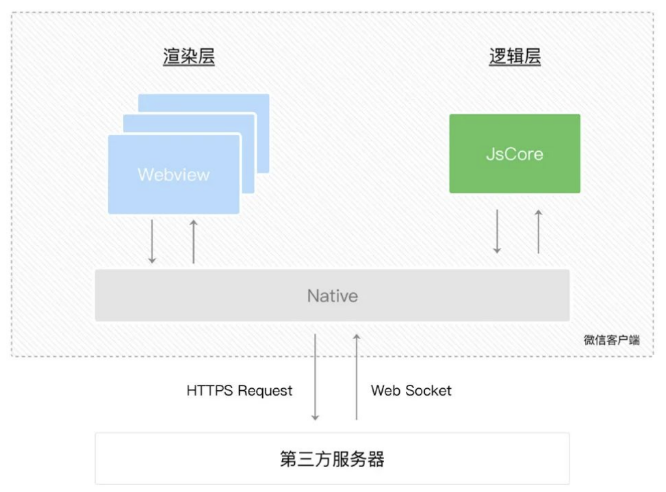
原理图:
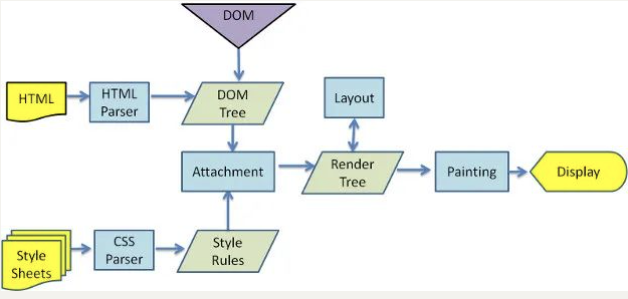
但是在这个执行过程中,HTML 解析的时候遇到了 JavaScript 标签,应该怎么办呢?
- 会停止解析 HTML,而去加载和执行 JavaScript 代码;
当然,为什么不直接异步去加载执行 JavaScript 代码,而要在这里停止掉呢?
- 这是因为 JavaScript 代码可以操作我们的 DOM;
- 所以浏览器希望将 HTML 解析的 DOM 和 JavaScript 操作之后的 DOM 放到一起来生成最终的 DOM 树,而不是频繁的去生成新的 DOM 树;
那么,JavaScript 代码由谁来执行呢?
- JavaScript 引擎
JS 引擎
JS 引擎作用: JS 引擎帮助我们将 JS 代码翻译成 CPU 指令来执行
事实上我们编写的 JavaScript 无论你交给浏览器或者 Node 执行,最后都是需要被 CPU 执行的。但是 CPU 只认识自己的指令集,实际上是机器语言,才能被 CPU 所执行。所以我们需要 JavaScript 引擎帮助我们将 JavaScript 代码翻译成 CPU 指令来执行。
常见 JS 引擎:
- SpiderMonkey:第一款 JavaScript 引擎,由 Brendan Eich 开发(也就是 JavaScript 作者);
- Chakra:微软开发,用于 IT 浏览器;
- JavaScriptCore:WebKit 中的 JavaScript 引擎,Apple 公司开发;
- V8:Google 开发的强大 JavaScript 引擎,也帮助 Chrome 从众多浏览器中脱颖而出;
另外一个强大的 JavaScript 引擎就是 V8 引擎。
V8
V8 定义: V8 是用 C ++编写的 Google 开源高性能 JavaScript 和 WebAssembly 引擎,它用于Chrome和Node.js等。它实现 ECMAScript 和 WebAssembly,并在 Windows 7 或更高版本,macOS 10.12+和使用 x64,IA-32,ARM 或 MIPS 处理器的 Linux 系统上运行。V8 可以独立运行,也可以嵌入到任何 C ++应用程序中。
原理图:
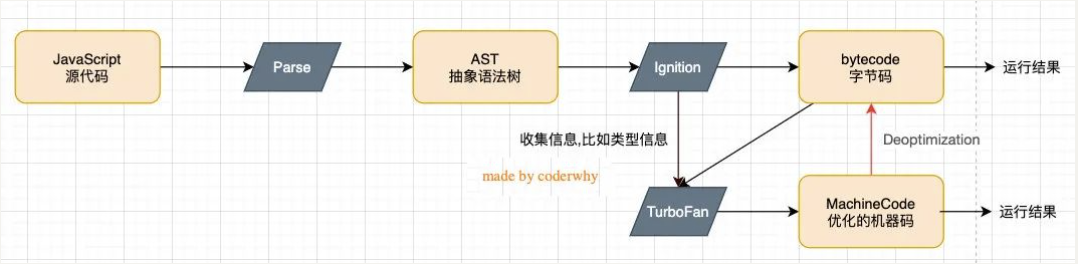
V8 引擎本身的源码非常复杂,大概有超过 100w 行 C++代码,但是我们可以简单了解一下它执行 JavaScript 代码的原理:
Parse模块会将 JS 代码转换成 AST(抽象语法树),这是因为解释器并不直接认识 JavaScript 代码;
*注意:*如果函数没有被调用,那么是不会被转换成 AST 的;
Parse 的 V8 官方文档:https://v8.dev/blog/scanner
Ignition是一个解释器,会将 AST 转换成 ByteCode(字节码),同时会收集 TurboFan 优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算)
- *注意:*如果函数只调用一次,Ignition 会执行解释执行 ByteCode;
- Ignition 的 V8 官方文档:https://v8.dev/blog/ignition-interpreter
TurboFan是一个编译器,可以将字节码编译为 CPU 可以直接执行的机器码;
注意: 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过 TurboFan 转换成优化的机器码,提高代码的执行性能;
但是,机器码实际上也会被还原为 ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如 sum 函数原来执行的是 number 类型,后来执行变成了 string 类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
TurboFan 的 V8 官方文档:https://v8.dev/blog/turbofan-jit
Orinoco 事实上 V8 的内存回收也是其强大的另外一个原因,这里暂时先不展开讨论:
- Orinoco 模块,负责垃圾回收,将程序中不需要的内存回收;
- Orinoco 的 V8 官方文档:https://v8.dev/blog/trash-talk
Node 基础
概述
概念: Node.js 是一个基于 V8 JavaScript 引擎的 JavaScript 运行时环境
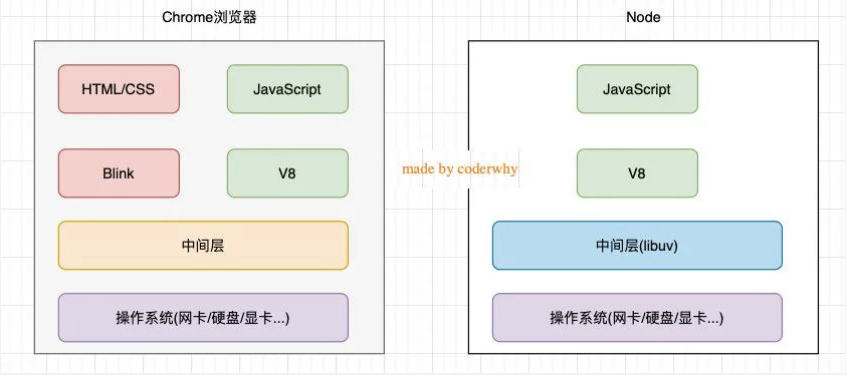
浏览器组成:
- V8 引擎:运行 JS
- DOM:解析渲染 HTML、CSS
- BOM:
Node 组成:
- V8 引擎
- 文件系统读/写
- 网络 IO
- 加密
- 压缩解压文件
浏览器、Node 组成:
Node 架构图:
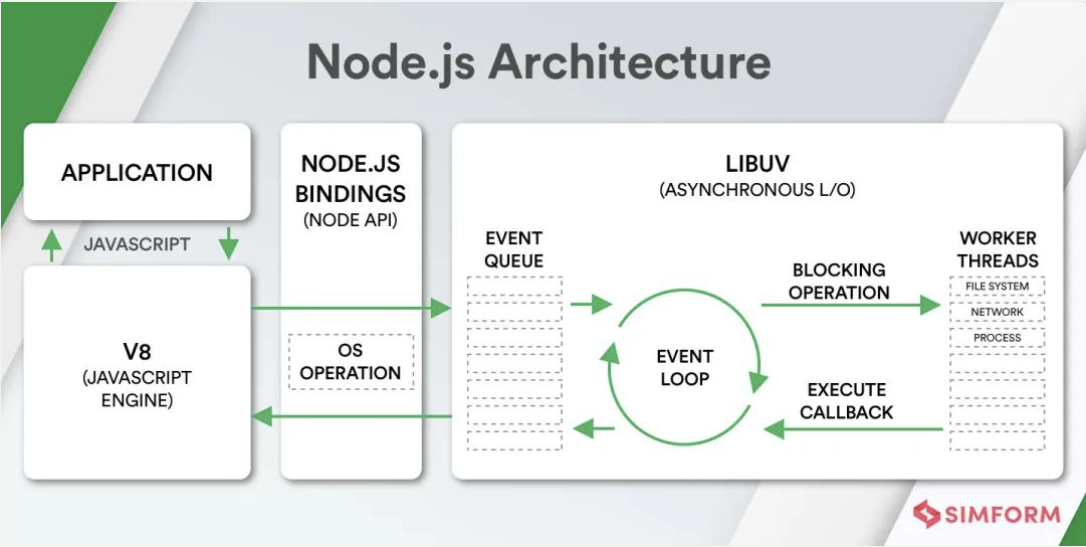
- 我们编写的 JavaScript 代码会经过 V8 引擎,再通过 Node.js 的 Bindings,将任务放到 Libuv 的事件循环中;
- libuv(Unicorn Velociraptor—独角伶盗龙)是使用 C 语言编写的库;
- libuv 提供了事件循环、文件系统读写、网络 IO、线程池等等内容;
- 具体内部代码的执行流程,我会在后续专门讲解事件和异步 IO 的原理中详细讲解;
应用场景:
- 包管理工具
- npm
- yarn
- pnpm
- 脚手架
- webpack
- gulp
- 服务器
- web 服务器
- 代理服务器
- 中间件
- SSR
- 脚本工具
- 工程自动化
- Electron
- vscode
依赖软件
依赖包: node
版本:
- LTS:稳定版
- Current:最新版
安装: 和在 windows 上安装其他软件一样
常用命令:
node --version,查看当前的版本node <path/index.js>,运行 index.js 文件
版本管理工具
n
介绍: Linux 环境的管理工具
安装: npm i n -g
常用命令:
n --version,查看安装的版本n lts,安装最新的 LTS 版本n latest,安装最新的版本n,查看所有的版本
nvm
介绍:Linux 环境的管理工具
nvm-window
介绍:Windows 环境的管理工具
常用命令:
查看 node
nvm list,查看所有安装的版本nvm list installed,显示所有已安装的版本nvm list available,显示所有可以下载的版本
安装 node
nvm install 16.9.0,安装 16.9.0 版本nvm install 16,安装 16 大版本的最新小版本nvm install lts,安装最新的 LTS 版本nvm install latest,安装最新的版本
卸载 node
nvm uninstall <版本号>,卸载指定版本的 node
使用指定版本的 node
nvm use <版本号>,使用指定版本的 node
查看 nvm 版本
nvm version,查看 nvm 版本nvm --version,查看 nvm 版本
终端
常用终端:
- CMD
- PowerShell
- Git Bash
- vscode
Node 的输入、输出
输入:
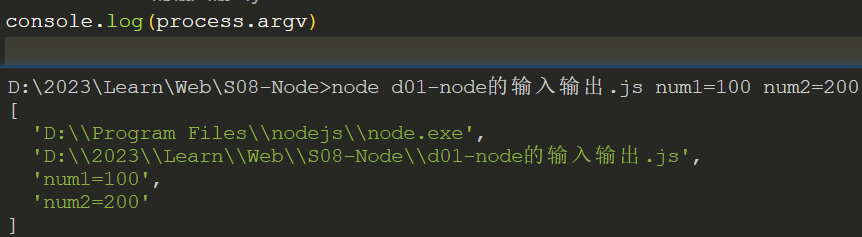
1、在终端中运行以下命令:node <index.js> num1=100 num2=200
2、在 js 中通过process.argv获取终端中输入的参数num1、num2
输出:
console.log('hello'),打印消息console.clear(),清空控制台console.trace(),打印执行调用栈
REPL
概念: REPL:Read-Eval-Print Loop,“读取-求值-输出”循环。它是一个简单的、交互式的编程环境
常用命令:
- 开启 REPL,
node + 回车 - 退出 REPL
Ctrl + C(按2次).exit
全局对象
环境变量
process.env
说明: 当前进程的环境变量
process.argv
说明: 一个包含命令行参数的数组。当在命令行中执行 Node.js 脚本时,可以使用该数组来访问传递给脚本的参数。
参数: 接受如下命令行中传递的参数:node <index.js> arg1=xxx arg2=xxx
返回值: 一个包含命令行参数的数组
- 第一个元素:Node.js 的可执行文件路径
- 第二个元素:被执行的 JavaScript 文件的路径
- 后续元素:命令行传递的参数
示例: process.argv


类似 window
window
说明: 浏览器环境下的全局对象,Node 环境下没有
注意: 通过 var 定义的变量,会被放入到 window 对象上
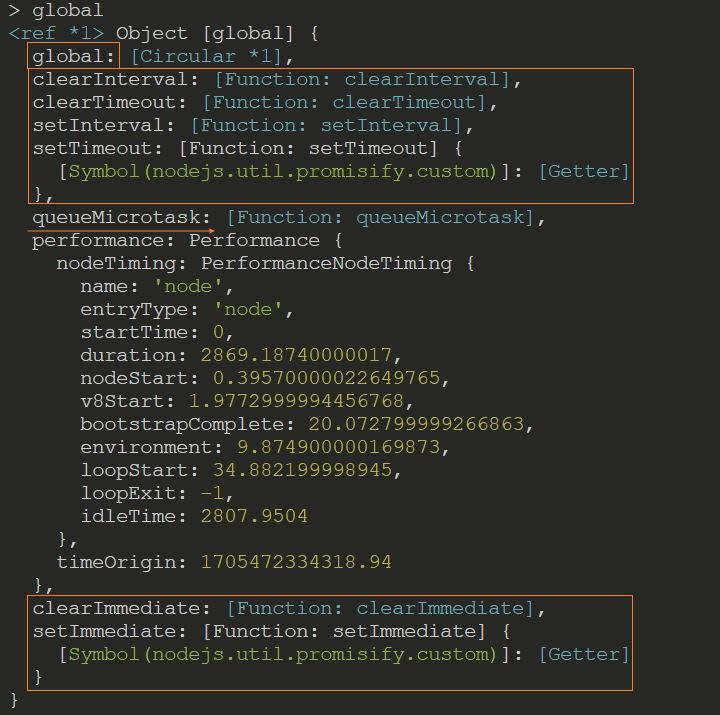
global
说明: Node 环境下的全局对象,浏览器环境下没有
注意: 通过 var 定义的变量,会被放入到 global 对象上
示例: global 对象
globalThis
说明: ES2020 新增。是一个跨平台的解决方案。浏览器和 Node 环境下分别指向全局对象 window 和 global
注意:
globalThis === global,Node 环境中二者等价globalThis === window,浏览器环境中二者等价
模块
注意: 以下实际上是模块中的变量
require()
说明: 用于加载和引用其他 JS 文件或模块
语法:
require(id)参数:
- id:
string,要加载的模块名称或路径
返回值:
- module:
any,已加载模块的对象
exports
说明: 包含模块导出内容的空对象。通过向 exports 对象添加属性或方法,可以将它们导出给其他模块使用。
语法:
exports.xxx = value
exports.xxx = function() { ... }
exports.xxx = () => { ... }module
说明: 表示当前模块的对象。每个 JS 文件都是一个独立的模块,可以通过 module 对象来访问和控制模块的行为。
语法:
module.exports = {
xxx: value
}属性:
- module.exports:导出模块内容给其他模块使用。
- module.id:表示当前模块的标识符,通常是文件的绝对路径。
- module.filename:表示当前模块的文件名,通常是文件的绝对路径。
- module.loaded:一个布尔值,表示当前模块是否已经加载完成。
- module.parent:表示当前模块的父级模块。
- module.children:表示当前模块依赖的子模块列表。
方法:
- module.require(id):类似于全局的
require()函数,用于加载和返回指定模块。
__dirname
说明: 当前文件所在目录(绝对路径)
语法:
// /home/user/projects/myapp/app.js
console.log(__dirname) // /home/user/projects/myapp__filename
说明: 当前文件所在目录+文件名称(绝对路径)
语法:
// /home/user/projects/myapp/app.js
console.log(__dirname) // /home/user/projects/myapp/app.jsURL
URLSearchParams
说明: 处理 URL 查询字符串的接口
语法:
const params = new URLSearchParams(init?)参数:
- init?:
string | object | URLSearchParams,被解析的目标string:它会被解析为查询参数,并用于初始化URLSearchParams对象。object:它会被解析为键值对,并用于初始化URLSearchParams对象。URLSearchParams:它会被复制到新的URLSearchParams对象。
返回值:
- params:
,一个URLSearchParams对象,可以使用URLSearchParams的方法来操作查询参数。
实例方法:
- params.append(name, value):向查询参数中添加一个新的键值对。
- params.delete(name):从查询参数中删除指定名称的键值对。
- params.get(name):返回查询参数中指定名称的第一个值。
- params.getAll(name):返回查询参数中指定名称的所有值的数组。
- params.has(name):检查查询参数中是否存在指定名称的键值对。
- params.set(name, value):将查询参数中指定名称的键值对设置为新的值。
- params.sort():按照名称对查询参数进行排序。
- params.toString():返回表示查询参数的字符串。
示例: 解析查询字符串
var baseUrl = 'http://example.com/search?query=tom&age=33'
const url = new URL(baseUrl)
// 获取查询字符串
const queryString = url.search // ?query=tom&age=33
// 方式一:获取 URLSearchParams 对象
const query = url.searchParams // URLSearchParams { 'query' => 'tom', 'age' => '33' }
// 方式二:获取 URLSearchParams 对象
const params = new URLSearchParams(query) // URLSearchParams { 'query' => 'tom', 'age' => '33' }
// 转化URLSearchParams为对象格式
console.log(Object.fromEntries(params)) // { query: 'tom', age: '33' }定时器
setTimeout()
setInterval()
setImmediate()
clearTimeout()
clearInterval()
clearImmediate()
事件循环
定时器
queueMicrotask()
process.nextTick()
console
console
模块化
概述
JavaScript 设计缺陷
那么,到底什么是模块化开发呢?
- 事实上模块化开发最终的目的是将程序划分成一个个小的结构;
- 这个结构中编写属于自己的逻辑代码,有自己的作用域,定义变量名称时不会影响到其他的结构;
- 这个结构可以将自己希望暴露的变量、函数、对象等导出给其结构使用;
- 也可以通过某种方式,导入另外结构中的变量、函数、对象等;
上面说提到的结构,就是模块;
按照这种结构划分开发程序的过程,就是模块化开发的过程;
无论你多么喜欢 JavaScript,以及它现在发展的有多好,我们都需要承认在Brendan Eich用了 10 天写出 JavaScript 的时候,它都有很多的缺陷:
- 比如 var 定义的变量作用域问题;
- 比如 JavaScript 的面向对象并不能像常规面向对象语言一样使用 class;
- 比如 JavaScript 没有模块化的问题;
Brendan Eich本人也多次承认过 JavaScript 设计之初的缺陷,但是随着 JavaScript 的发展以及标准化,存在的缺陷问题基本都得到了完善。
- JavaScript 目前已经得到了快速的发展,无论是 web、移动端、小程序端、服务器端、桌面应用都被广泛的使用;
在网页开发的早期,Brendan Eich开发 JavaScript 仅仅作为一种脚本语言,做一些简单的表单验证或动画实现等,那个时候代码还是很少的:
- 这个时候我们只需要讲 JavaScript 代码写到
<script>标签中即可; - 并没有必要放到多个文件中来编写;
<button id="btn">按钮</button>
<script>
document.getElementById("btn").onclick = function() {
console.log("按钮被点击了");
}
</script>但是随着前端和 JavaScript 的快速发展,JavaScript 代码变得越来越复杂了:
- ajax 的出现,前后端开发分离,意味着后端返回数据后,我们需要通过 JavaScript 进行前端页面的渲染;
- SPA 的出现,前端页面变得更加复杂:包括前端路由、状态管理等等一系列复杂的需求需要通过 JavaScript 来实现;
- 包括 Node 的实现,JavaScript 编写复杂的后端程序,没有模块化是致命的硬伤;
所以,模块化已经是 JavaScript 一个非常迫切的需求:
- 但是 JavaScript 本身,直到 ES6(2015)才推出了自己的模块化方案;
- 在此之前,为了让 JavaScript 支持模块化,涌现出了很多不同的模块化规范:AMD、CMD、CommonJS 等;
在这个章节,我们将详细学习 JavaScript 的模块化,尤其是 CommonJS 和 ES6 的模块化。
没有模块化的问题
我们先来简单体会一下没有模块化代码的问题。
我们知道,对于一个大型的前端项目,通常是多人开发的(即使一个人开发,也会将代码划分到多个文件夹中):
- 我们假设有两个人:小明和小丽同时在开发一个项目,并且会将自己的 JavaScript 代码放在一个单独的 js 文件中。
小明开发了 aaa.js 文件,代码如下(当然真实代码会复杂的多):
var flag = true;
if (flag) {
console.log("aaa的flag为true")
}小丽开发了 bbb.js 文件,代码如下:
var flag = false;
if (!flag) {
console.log("bbb使用了flag为false");
}很明显出现了一个问题:
- 大家都喜欢使用 flag 来存储一个 boolean 类型的值;
- 但是一个人赋值了 true,一个人赋值了 false;
- 如果之后都不再使用,那么也没有关系;
但是,小明又开发了 ccc.js 文件:
if (flag) {
console.log("使用了aaa的flag");
}问题来了:小明发现 ccc 中的 flag 值不对
- 对于聪明的你,当然一眼就看出来,是小丽将 flag 赋值为了 false;
- 但是如果每个文件都有上千甚至更多的代码,而且有上百个文件,你可以一眼看出来 flag 在哪个地方被修改了吗?
备注:引用路径如下:
<script src="./aaa.js"></script>
<script src="./bbb.js"></script>
<script src="./ccc.js"></script>所以,没有模块化对于一个大型项目来说是灾难性的。
当然,我们有办法可以解决上面的问题:立即函数调用表达式(IIFE)
- IIFE (Immediately Invoked Function Expression)
aaa.js
const moduleA = (function () {
var flag = true;
if (flag) {
console.log("aaa的flag为true")
}
return {
flag: flag
}
})();bbb.js
const moduleB = (function () {
var flag = false;
if (!flag) {
console.log("bbb使用了flag为false");
}
})();ccc.js
const moduleC = (function() {
const flag = moduleA.flag;
if (flag) {
console.log("使用了aaa的flag");
}
})();命名冲突的问题,有没有解决呢?解决了。
但是,我们其实带来了新的问题:
- 第一,我必须记得每一个模块中返回对象的命名,才能在其他模块使用过程中正确的使用;
- 第二,代码写起来混乱不堪,每个文件中的代码都需要包裹在一个匿名函数中来编写;
- 第三,在没有合适的规范情况下,每个人、每个公司都可能会任意命名、甚至出现模块名称相同的情况;
所以,我们会发现,虽然实现了模块化,但是我们的实现过于简单,并且是没有规范的。
- 我们需要制定一定的规范来约束每个人都按照这个规范去编写模块化的代码;
- 这个规范中应该包括核心功能:模块本身可以导出暴露的属性,模块又可以导入自己需要的属性;
JavaScript 社区为了解决上面的问题,涌现出一系列好用的规范,接下来我们就学习具有代表性的一些规范。
CommonJS 规范
CommonJS 和 Node
我们需要知道CommonJS 是一个规范,最初提出来是在浏览器以外的地方使用,并且当时被命名为ServerJS,后来为了体现它的广泛性,修改为CommonJS,平时我们也会简称为CJS。
- Node是 CommonJS 在服务器端一个具有代表性的实现;
- Browserify是 CommonJS 在浏览器中的一种实现;
- webpack打包工具具备对 CommonJS 的支持和转换(后面我会讲到);
所以,Node 中对 CommonJS 进行了支持和实现,让我们在开发 node 的过程中可以方便的进行模块化开发:
- 在 Node 中每一个 js 文件都是一个单独的模块;
- 这个模块中包括 CommonJS 规范的核心变量:exports、module.exports、require;
- 我们可以使用这些变量来方便的进行模块化开发;
前面我们提到过模块化的核心是导出和导入,Node 中对其进行了实现:
- exports 和 module.exports 可以负责对模块中的内容进行导出;
- require 函数可以帮助我们导入其他模块(自定义模块、系统模块、第三方库模块)中的内容;
Node 模块化开发
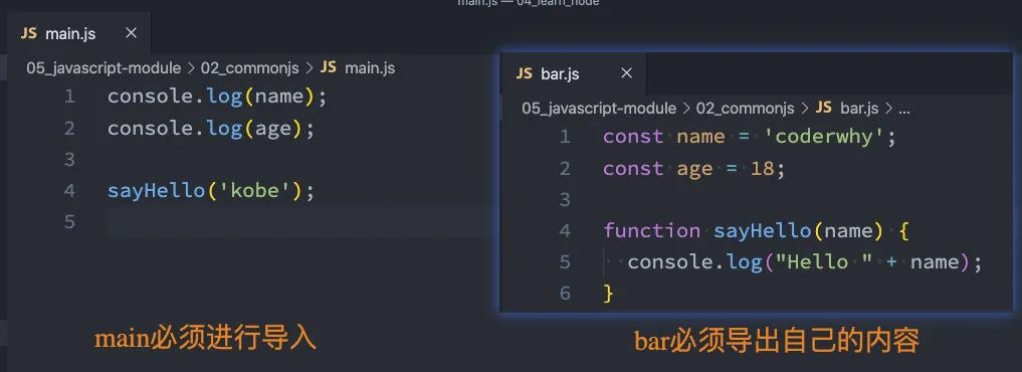
我们来看一下两个文件:
bar.js
const name = 'coderwhy';
const age = 18;
function sayHello(name) {
console.log("Hello " + name);
}main.js
console.log(name);
console.log(age);
sayHello('kobe');上面的代码会报错:
- 在 node 中每一个文件都是一个独立的模块,有自己的作用域;
- 那么,就意味着别的模块 main 中不能随便访问另外一个模块 bar 中的内容;
- bar 需要导出自己想要暴露的变量、函数、对象等等;
- main 从 bar 中导入自己想要使用的变量、函数、对象等等;
导出和导入
exports 导出
强调:exports 是一个对象,我们可以在这个对象中添加很多个属性,添加的属性会导出
bar.js 中导出内容:
exports.name = name;
exports.age = age;
exports.sayHello = sayHello;main.js 中导入内容:
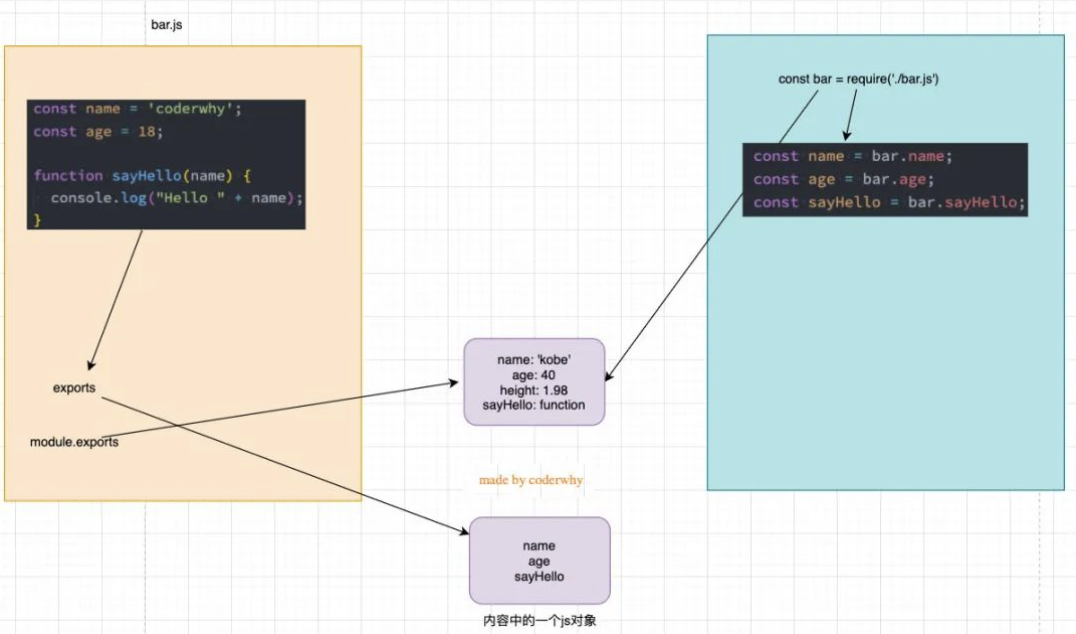
const bar = require('./bar');上面这行代码意味着什么呢?
- 意味着 main 中的 bar 变量等于 exports 对象;
main中的bar = bar中的exports所以,我可以编写下面的代码:
const bar = require('./bar');
const name = bar.name;
const age = bar.age;
const sayHello = bar.sayHello;
console.log(name);
console.log(age);
sayHello('kobe');模块之间的引用关系
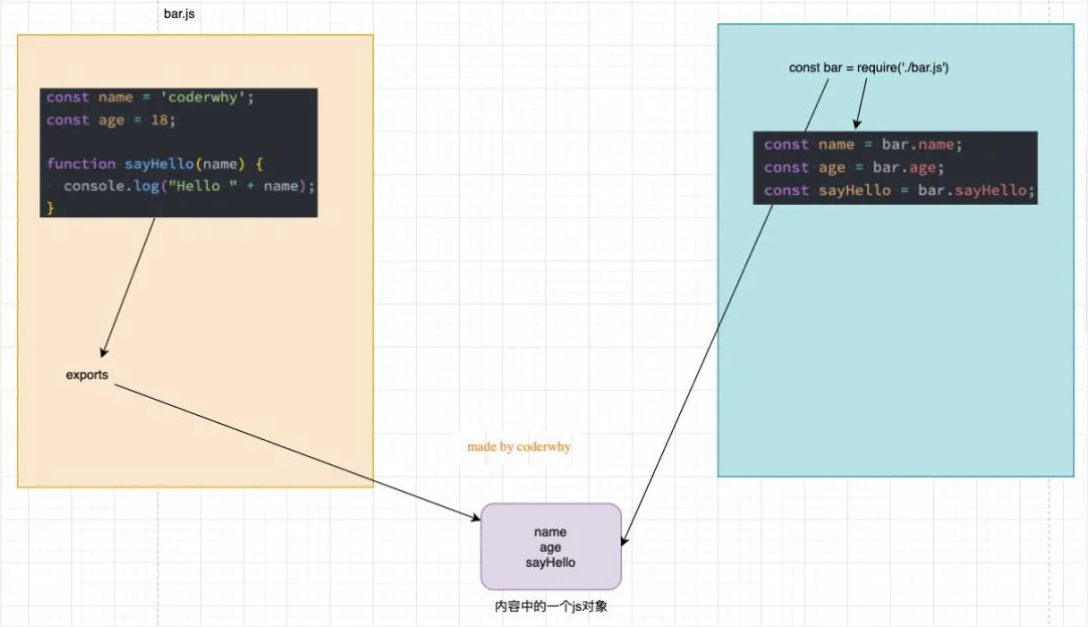
为了进一步论证,bar 和 exports 是同一个对象:
- 所以,bar 对象是 exports 对象的浅拷贝;
- 浅拷贝的本质就是一种引用的赋值而已;
定时器修改对象
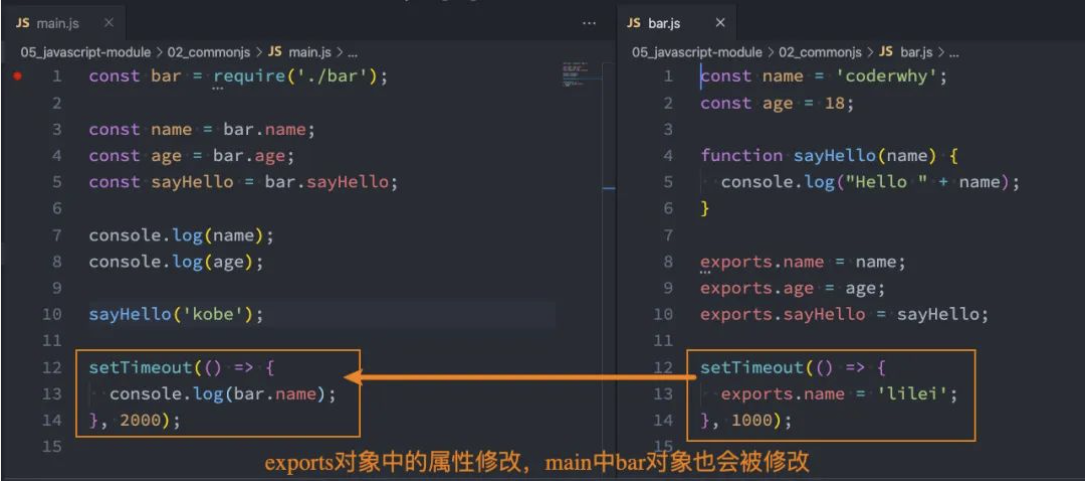
module.exports
但是 Node 中我们经常导出东西的时候,又是通过 module.exports 导出的:
- module.exports 和 exports 有什么关系或者区别呢?
我们追根溯源,通过维基百科中对 CommonJS 规范的解析:
- CommonJS 中是没有 module.exports 的概念的;
- 但是为了实现模块的导出,Node 中使用的是 Module 的类,每一个模块都是 Module 的一个实例,也就是 module;
- 所以在 Node 中真正用于导出的其实根本不是 exports,而是 module.exports;
- 因为 module 才是导出的真正实现者;
但是,为什么 exports 也可以导出呢?
- 这是因为 module 对象的 exports 属性是 exports 对象的一个引用;
- 也就是说
module.exports = exports = main中的bar;
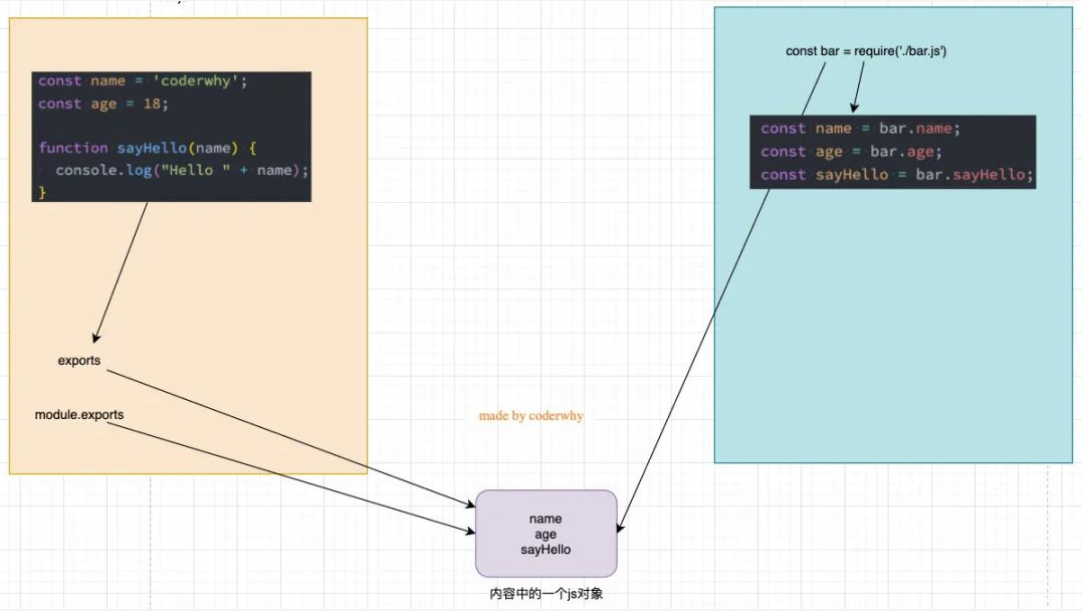
注意:真正导出的模块内容的核心其实是 module.exports,只是为了实现 CommonJS 的规范,刚好 module.exports 对 exports 对象有一个引用而已;
那么,如果我的代码这样修改了:
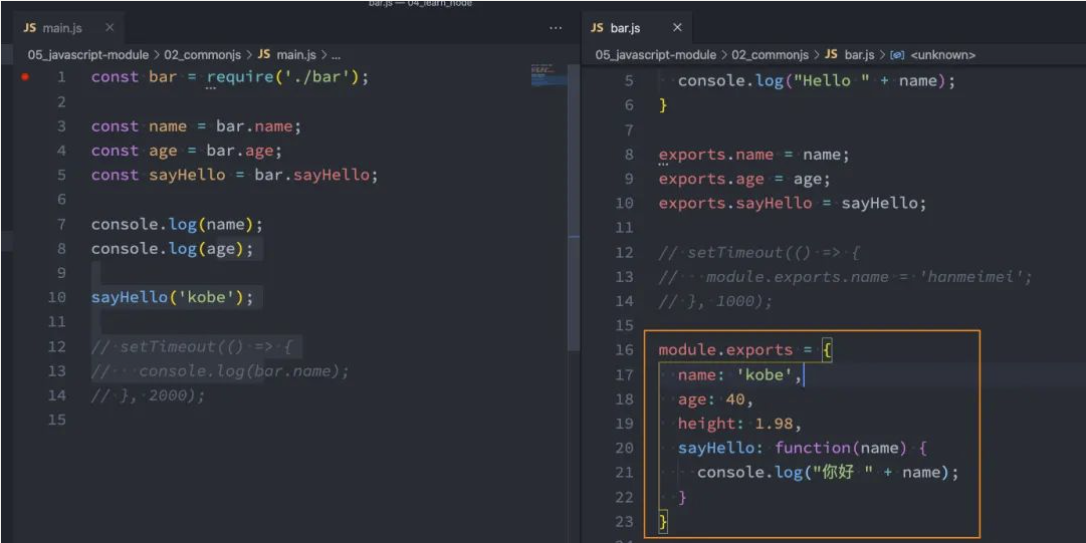
你能猜到内存中会有怎么样的表现吗?
- 结论:和 exports 对象没有任何关系了,exports 你随便玩自己的吧;
- module.exports 我现在导出一个自己的对象,不带着你玩了;
- 新的对象取代了 exports 对象的导出,那么就意味着 require 导入的对象是新的对象;
require 细节
我们现在已经知道,require 是一个函数,可以帮助我们引入一个文件(模块)中导入的对象。
那么,require 的查找规则是怎么样的呢?
这里我总结比较常见的查找规则:
导入格式如下:require(X)
情况一:X 是一个核心模块,比如 path、http
- 直接返回核心模块,并且停止查找
情况二:X 是以
./或../或/(根目录)开头的- 查找目录下面的 index 文件
- 1> 查找 X/index.js 文件
- 2> 查找 X/index.json 文件
- 3> 查找 X/index.node 文件
- 1.如果有后缀名,按照后缀名的格式查找对应的文件
- 2.如果没有后缀名,会按照如下顺序:
- 1> 直接查找文件 X
- 2> 查找 X.js 文件
- 3> 查找 X.json 文件
- 4> 查找 X.node 文件
- 第一步:将 X 当做一个文件在对应的目录下查找;
- 第二步:没有找到对应的文件,将 X 作为一个目录
- 如果没有找到,那么报错:
not found
情况三:直接是一个 X(没有路径),并且 X 不是一个核心模块
比如
/Users/coderwhy/Desktop/Node/TestCode/04_learn_node/05_javascript-module/02_commonjs/main.js中编写require('why')查找顺序
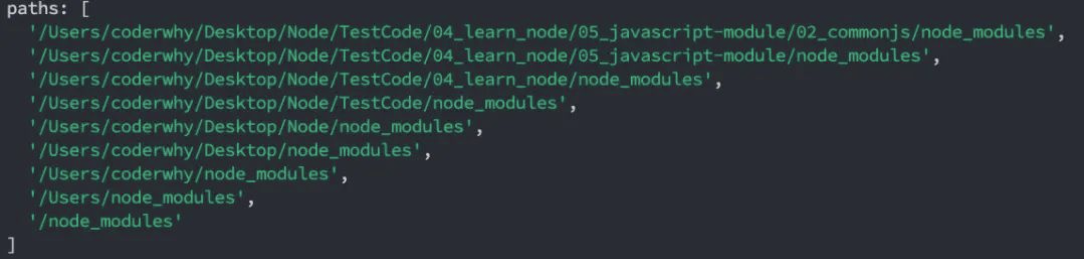
如果上面的路径中都没有找到,那么报错:
not found
模块加载顺序
这里我们研究一下模块的加载顺序问题。
结论一:模块在被第一次引入时,模块中的 js 代码会被运行一次
aaa.js
const name = 'coderwhy';
console.log("Hello aaa");
setTimeout(() => {
console.log("setTimeout");
}, 1000);main.js
const aaa = require('./aaa');aaa.js 中的代码在引入时会被运行一次
结论二:模块被多次引入时,会缓存,最终只加载(运行)一次
main.js
const aaa = require('./aaa');
const bbb = require('./bbb');aaa.js
const ccc = require("./ccc");bbb.js
const ccc = require("./ccc");ccc.js
console.log('ccc被加载');ccc 中的代码只会运行一次。
为什么只会加载运行一次呢?
- 这是因为每个模块对象 module 都有一个属性:loaded。
- 为 false 表示还没有加载,为 true 表示已经加载;
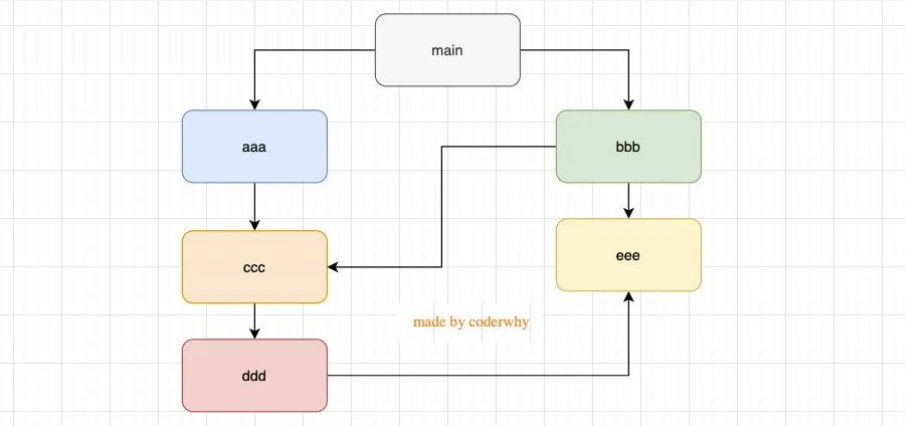
结论三:如果有循环引入,那么加载顺序是什么?
如果出现下面模块的引用关系,那么加载顺序是什么呢?
- 这个其实是一种数据结构:图结构;
- 图结构在遍历的过程中,有深度优先搜索(DFS, depth first search)和广度优先搜索(BFS, breadth first search);
- Node 采用的是深度优先算法:main -> aaa -> ccc -> ddd -> eee ->bbb
多个模块的引入关系
Node 的源码解析
Module 类
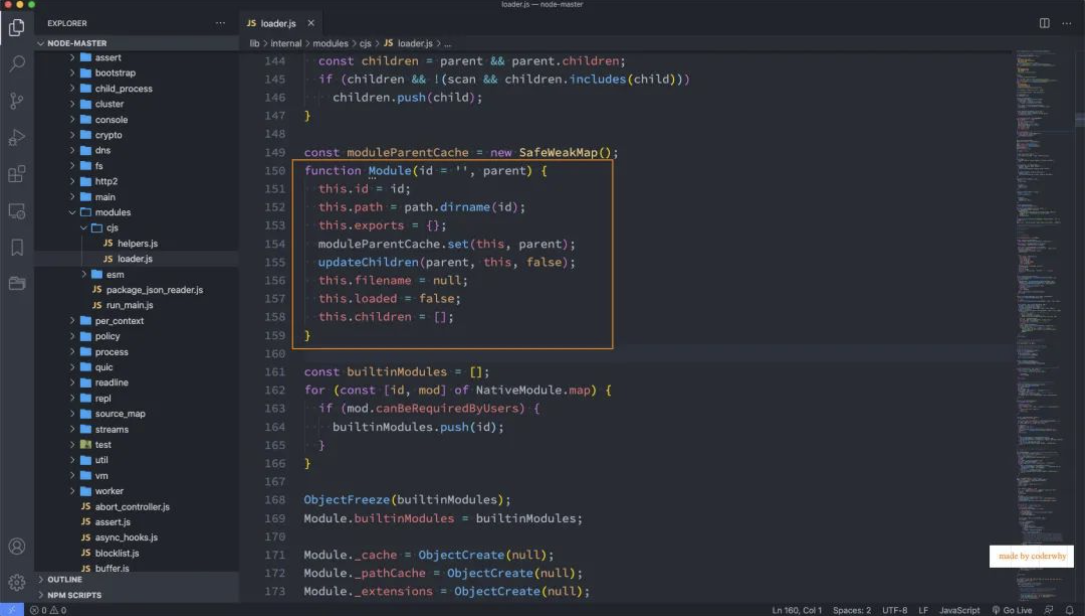
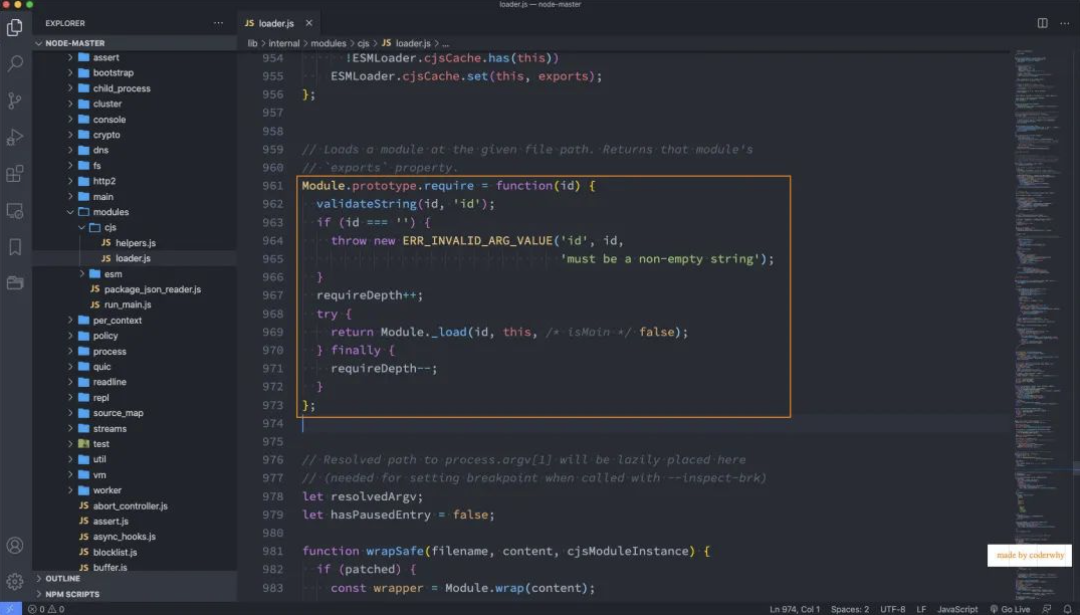
Module.prototype.require 函数
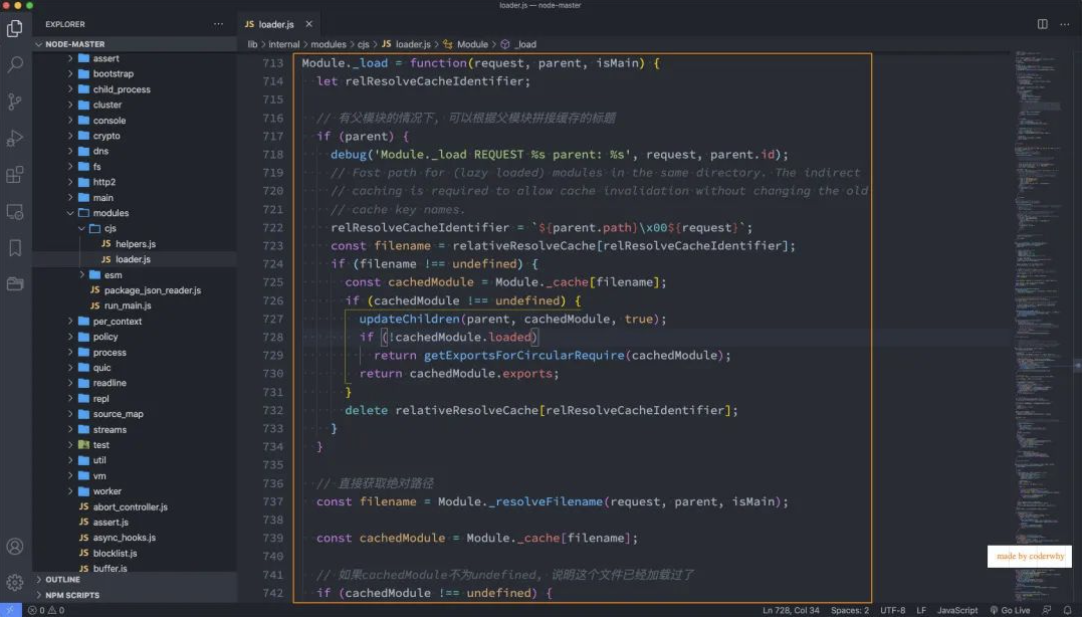
Module._load 函数
AMD 和 CMD 规范
CommonJS 规范缺点
CommonJS 加载模块是同步的:
- 同步的意味着只有等到对应的模块加载完毕,当前模块中的内容才能被运行;
- 这个在服务器不会有什么问题,因为服务器加载的 js 文件都是本地文件,加载速度非常快;
如果将它应用于浏览器呢?
- 浏览器加载 js 文件需要先从服务器将文件下载下来,之后在加载运行;
- 那么采用同步的就意味着后续的 js 代码都无法正常运行,即使是一些简单的 DOM 操作;
所以在浏览器中,我们通常不使用 CommonJS 规范:
- 当然在 webpack 中使用 CommonJS 是另外一回事;
- 因为它会将我们的代码转成浏览器可以直接执行的代码;
在早期为了可以在浏览器中使用模块化,通常会采用 AMD 或 CMD:
- 但是目前一方面现代的浏览器已经支持 ES Modules,另一方面借助于 webpack 等工具可以实现对 CommonJS 或者 ES Module 代码的转换;
- AMD 和 CMD 已经使用非常少了,所以这里我们进行简单的演练;
AMD 规范
AMD 主要是应用于浏览器的一种模块化规范:
- AMD 是 Asynchronous Module Definition(异步模块定义)的缩写;
- 它采用的是异步加载模块;
- 事实上 AMD 的规范还要早于 CommonJS,但是 CommonJS 目前依然在被使用,而 AMD 使用的较少了;
我们提到过,规范只是定义代码的应该如何去编写,只有有了具体的实现才能被应用:
- AMD 实现的比较常用的库是 require.js 和 curl.js;
这里我们以 require.js 为例讲解:
第一步:下载 require.js
- 下载地址:https://github.com/requirejs/requirejs
- 找到其中的 require.js 文件;
第二步:定义 HTML 的 script 标签引入 require.js 和定义入口文件:
- data-main 属性的作用是在加载完 src 的文件后会加载执行该文件
<script src="./lib/require.js" data-main="./index.js"></script>第三步:编写如下目录和代码
├── index.html
├── index.js
├── lib
│ └── require.js
└── modules
├── bar.js
└── foo.jsindex.js
;(function () {
require.config({
baseUrl: '',
paths: {
foo: './modules/foo',
bar: './modules/bar'
}
})
// 开始加载执行foo模块的代码
require(['foo'], function (foo) {})
})()modules/bar.js
- 如果一个模块不依赖其他,那么直接使用 define(function)即可
define(function () {
const name = 'coderwhy'
const age = 18
const sayHello = function (name) {
console.log('Hello ' + name)
}
return {
name,
age,
sayHello
}
})modules/foo.js
define(['bar'], function (bar) {
console.log(bar.name)
console.log(bar.age)
bar.sayHello('kobe')
})CMD 规范
CMD 规范也是应用于浏览器的一种模块化规范:
- CMD 是 Common Module Definition(通用模块定义)的缩写;
- 它也采用了异步加载模块,但是它将 CommonJS 的优点吸收了过来;
- 但是目前 CMD 使用也非常少了;
CMD 也有自己比较优秀的实现方案:
- SeaJS
我们一起看一下 SeaJS 如何使用:
第一步:下载 SeaJS
- 下载地址:https://github.com/seajs/seajs
- 找到 dist 文件夹下的 sea.js
第二步:引入 sea.js 和使用主入口文件
seajs是指定主入口文件的
<script src="./lib/sea.js"></script>
<script>
seajs.use('./index.js');
</script>第三步:编写如下目录和代码
├── index.html
├── index.js
├── lib
│ └── sea.js
└── modules
├── bar.js
└── foo.jsindex.js
define(function (require, exports, module) {
const foo = require('./modules/foo')
})bar.js
define(function (require, exports, module) {
const name = 'lilei'
const age = 20
const sayHello = function (name) {
console.log('你好 ' + name)
}
module.exports = {
name,
age,
sayHello
}
})foo.js
define(function (require, exports, module) {
const bar = require('./bar')
console.log(bar.name)
console.log(bar.age)
bar.sayHello('韩梅梅')
})ES Module
认识 ES Module
JavaScript 没有模块化一直是它的痛点,所以才会产生我们前面学习的社区规范:CommonJS、AMD、CMD 等,所以在 ES 推出自己的模块化系统时,大家也是兴奋异常。
ES Module和CommonJS的模块化有一些不同之处:
- 一方面它使用 import 和 export 关键字;
- 另一方面它采用编译期静态类型检测,并且动态引用的方式;
ES Module 模块采用 export 和 import 关键字来实现模块化:
- export 负责将模块内的内容导出;
- import 负责从其他模块导入内容;
了解:采用 ES Module 将自动采用严格模式:use strict
- 如果你不熟悉严格模式可以简单看一下 MDN 上的解析;
- https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Strict_mode
ES Module 的使用
代码结构组件
这里我在浏览器中演示 ES6 的模块化开发:
代码结构如下:
├── index.html
├── main.js
└── modules
└── foo.jsindex.html 中引入两个 js 文件作为模块:
<script src="./modules/foo.js" type="module"></script>
<script src="main.js" type="module"></script>如果直接在浏览器中运行代码,会报如下错误:

这个在 MDN 上面有给出解释:
- https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Modules
- 你需要注意本地测试 — 如果你通过本地加载 Html 文件 (比如一个
file://路径的文件), 你将会遇到 CORS 错误,因为 Javascript 模块安全性需要。 - 你需要通过一个服务器来测试。
我这里使用的 VSCode,VSCode 中有一个插件:Live Server
- 通过插件运行,可以将我们的代码运行在一个本地服务中;
export 关键字
export 关键字将一个模块中的变量、函数、类等导出;
foo.js 文件中默认代码如下:
const name = 'coderwhy';
const age = 18;
let message = "my name is why";
function sayHello(name) {
console.log("Hello " + name);
}我们希望将其他中内容全部导出,它可以有如下的方式:
方式一:在语句声明的前面直接加上 export 关键字
export const name = 'coderwhy';
export const age = 18;
export let message = "my name is why";
export function sayHello(name) {
console.log("Hello " + name);
}方式二:将所有需要导出的标识符,放到 export 后面的 {}中
- 所以:
export {name: name},是错误的写法;
const name = 'coderwhy';
const age = 18;
let message = "my name is why";
function sayHello(name) {
console.log("Hello " + name);
}
export {
name,
age,
message,
sayHello
}方式三:导出时给标识符起一个别名
export {
name as fName,
age as fAge,
message as fMessage,
sayHello as fSayHello
}import 关键字
import 关键字负责从另外一个模块中导入内容
导入内容的方式也有多种:
方式一:import {标识符列表} from '模块';
- 注意:这里的
{}也不是一个对象,里面只是存放导入的标识符列表内容;
import { name, age, message, sayHello } from './modules/foo.js';
console.log(name)
console.log(message);
console.log(age);
sayHello("Kobe");方式二:导入时给标识符起别名
import { name as wName, age as wAge, message as wMessage, sayHello as wSayHello } from './modules/foo.js';方式三:将模块功能放到一个模块功能对象(a module object)上
import * as foo from './modules/foo.js';
console.log(foo.name);
console.log(foo.message);
console.log(foo.age);
foo.sayHello("Kobe");export 和 import 结合
如果从一个模块中导入的内容,我们希望再直接导出出去,这个时候可以直接使用 export 来导出。
bar.js 中导出一个 sum 函数:
export const sum = function(num1, num2) {
return num1 + num2;
}foo.js 中导入,但是只是做一个中转:
export { sum } from './bar.js';main.js 直接从 foo 中导入:
import { sum } from './modules/foo.js';
console.log(sum(20, 30));甚至在 foo.js 中导出时,我们可以变化它的名字
export { sum as barSum } from './bar.js';为什么要这样做呢?
- 在开发和封装一个功能库时,通常我们希望将暴露的所有接口放到一个文件中;
- 这样方便指定统一的接口规范,也方便阅读;
- 这个时候,我们就可以使用 export 和 import 结合使用;
default 用法
前面我们学习的导出功能都是有名字的导出(named exports):
- 在导出 export 时指定了名字;
- 在导入 import 时需要知道具体的名字;
还有一种导出叫做默认导出(default export)
- 默认导出 export 时可以不需要指定名字;
- 在导入时不需要使用
{},并且可以自己来指定名字; - 它也方便我们和现有的 CommonJS 等规范相互操作;
导出格式如下:
export default function sub(num1, num2) {
return num1 - num2;
}导入格式如下:
import sub from './modules/foo.js';
console.log(sub(20, 30));注意:在一个模块中,只能有一个默认导出(default export);
import()
通过 import 加载一个模块,是不可以将其放到逻辑代码中的,比如:
if (true) {
import sub from './modules/foo.js'
}为什么会出现这个情况呢?
- 这是因为 ES Module 在被 JS 引擎解析时,就必须知道它的依赖关系;
- 由于这个时候 js 代码没有任何的运行,所以无法在进行类似于 if 判断中根据代码的执行情况;
- 甚至下面的这种写法也是错误的:因为我们必须到运行时能确定 path 的值;
const path = './modules/foo.js';
import sub from path;但是某些情况下,我们确确实实希望动态的来加载某一个模块:
- 如何根据不同的条件,动态来选择加载模块的路径;
- 这个时候我们需要使用
import()函数来动态加载;
aaa.js 模块:
export function aaa() {
console.log('aaa被打印')
}bbb.js 模块:
export function bbb() {
console.log('bbb被执行')
}main.js 模块:
let flag = true
if (flag) {
import('./modules/aaa.js').then((aaa) => {
aaa.aaa()
})
} else {
import('./modules/bbb.js').then((bbb) => {
bbb.bbb()
})
}import.meta@ES11【@
import.meta 提供了与当前模块的元数据相关的信息。
import.meta 只能在模块作用域中使用。
import.meta 是一个只读的对象,能够根据不同的环境提供一些元数据。
API:
通用属性
import.meta.url:
,返回的是当前模块的文件绝对路径。file:
string,当前模块的文件绝对路径。格式为:file:///path/to/currentModule.js- js
// 1. 获取当前模块的 URL // currentModule.js console.log(import.meta.url); // 输出:当前模块的绝对 URL,例如:file:///path/to/currentModule.js - js
// 2. 动态加载相对路径的资源 // currentModule.js const imageUrl = new URL('image.png', import.meta.url); console.log(imageUrl.href); // 输出:file:///path/to/currentModule/image.png - js
// 3. 使用 import.meta.url 动态导入模块 // currentModule.js const modulePath = `${import.meta.url}/moduleB.js`; import(modulePath).then((module) => { console.log(module); }).catch((err) => { console.error('Failed to load module:', err); }); - js
// 4. 结合 fileURLToPath() 设置@别名 export default defineConfig({ resolve: { alias: { '@': fileURLToPath(new URL('./src', import.meta.url)) }, }, }) // 说明:fileURLToPath()返回的是常用的系统文件路径格式:C:\dev\my_module.ts
import.meta.scriptElement:
,用于在JS模块环境中获取当前<script>元素的引用。常用在模块化script环境中:<script type="module">返回:
script:
HTMLScriptElement | undefined,返回当前<script>元素的引用。如果脚本不是通过<script type="module">标签加载的,或者脚本没有关联import.meta.scriptElement,返回undefined。- js
// HTML 代码为 // <script type="module" src="my-module.js" data-foo="abc"></script> // my-module.js 内部执行下面的代码 import.meta.scriptElement.dataset.foo // "abc"
vite、webpack、rollup特有属性
import.meta.env:
,用于访问在构建过程中注入的环境变量。返回:
env:``,返回环境变量。
- js
// 1. 环境模式切换 if (import.meta.env.MODE === 'development') { console.log('开发模式'); // 开发模式下的操作 } else if (import.meta.env.MODE === 'production') { console.log('生产模式'); // 生产模式下的操作 } - js
// 2. 访问自定义环境变量 // 在.env中自定义变量 VITE_API_URL=https://api.example.com VITE_APP_VERSION=1.0.0 // 在代码中访问 console.log(import.meta.env.VITE_API_URL); // 输出:https://api.example.com console.log(import.meta.env.VITE_APP_VERSION); // 输出:1.0.0
vite特有属性
import.meta.glob:
(),- https://vitejs.cn/vite5-cn/guide/features.html#glob-import
- :``,
- :``,
- 注意: webpack中类似的方法:
require.context()。 - 返回:
- :``,
开发者使用一个模块时,有时需要知道模板本身的一些信息(比如模块的路径)。ES2020 为 import 命令添加了一个元属性import.meta,返回当前模块的元信息。
import.meta只能在模块内部使用,如果在模块外部使用会报错。
这个属性返回一个对象,该对象的各种属性就是当前运行的脚本的元信息。具体包含哪些属性,标准没有规定,由各个运行环境自行决定。一般来说,import.meta至少会有下面两个属性。
import.meta.url
import.meta.url返回当前模块的 URL 路径。举例来说,当前模块主文件的路径是https://foo.com/main.js,import.meta.url就返回这个路径。如果模块里面还有一个数据文件data.txt,那么就可以用下面的代码,获取这个数据文件的路径。
new URL('data.txt', import.meta.url)注意,Node.js 环境中,import.meta.url返回的总是本地路径,即file:URL协议的字符串,比如file:///home/user/foo.js。
import.meta.scriptElement
import.meta.scriptElement是浏览器特有的元属性,返回加载模块的那个<script>元素,相当于document.currentScript属性。
// HTML 代码为
// <script type="module" src="my-module.js" data-foo="abc"></script>
// my-module.js 内部执行下面的代码
import.meta.scriptElement.dataset.foo
// "abc"(3)其他
Deno 现在还支持import.meta.filename和import.meta.dirname属性,对应 CommonJS 模块系统的__filename和__dirname属性。
import.meta.filename:当前模块文件的绝对路径。import.meta.dirname:当前模块文件的目录的绝对路径。
这两个属性都提供当前平台的正确的路径分隔符,比如 Linux 系统返回/dev/my_module.ts,Windows 系统返回C:\dev\my_module.ts。
本地模块可以使用这两个属性,远程模块也可以使用。
ES Module 的原理
ES Module 和 CommonJS 的区别
CommonJS 模块加载 js 文件的过程是运行时加载的,并且是同步的:
- 运行时加载意味着是 js 引擎在执行 js 代码的过程中加载 模块;
- 同步的就意味着一个文件没有加载结束之前,后面的代码都不会执行;
console.log("main代码执行");
const flag = true;
if (flag) {
// 同步加载foo文件,并且执行一次内部的代码
const foo = require('./foo');
console.log("if语句继续执行");
}CommonJS 通过 module.exports 导出的是一个对象:
- 导出的是一个对象意味着可以将这个对象的引用在其他模块中赋值给其他变量;
- 但是最终他们指向的都是同一个对象,那么一个变量修改了对象的属性,所有的地方都会被修改;
ES Module 加载 js 文件的过程是编译(解析)时加载的,并且是异步的:
编译时(解析)时加载,意味着 import 不能和运行时相关的内容放在一起使用:
- 比如 from 后面的路径需要动态获取;
- 比如不能将 import 放到 if 等语句的代码块中;
- 所以我们有时候也称 ES Module 是静态解析的,而不是动态或者运行时解析的;
异步的意味着:JS 引擎在遇到
import时会去获取这个 js 文件,但是这个获取的过程是异步的,并不会阻塞主线程继续执行;- 也就是说设置了
type=module的代码,相当于在 script 标签上也加上了async属性; - 如果我们后面有普通的 script 标签以及对应的代码,那么 ES Module 对应的 js 文件和代码不会阻塞它们的执行;
- 也就是说设置了
<script src="main.js" type="module"></script>
<!-- 这个js文件的代码不会被阻塞执行 -->
<script src="index.js"></script>ES Module 通过 export 导出的是变量本身的引用:
- export 在导出一个变量时,js 引擎会解析这个语法,并且创建模块环境记录(module environment record);
- 模块环境记录会和变量进行
绑定(binding),并且这个绑定是实时的; - 而在导入的地方,我们是可以实时的获取到绑定的最新值的;
export 和 import 绑定的过程
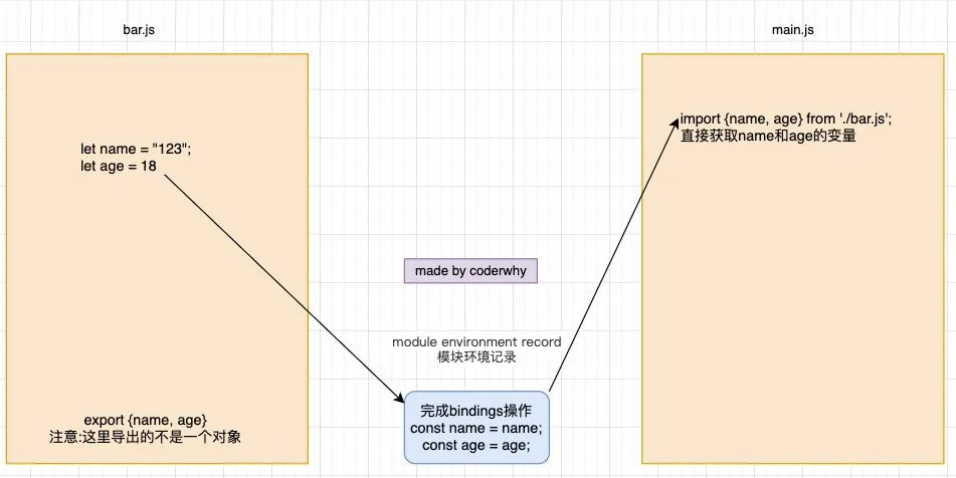
所以我们下面的代码是成立的:
bar.js 文件中修改
let name = 'coderwhy';
setTimeout(() => {
name = "湖人总冠军";
}, 1000);
setTimeout(() => {
console.log(name);
}, 2000);
export {
name
}main.js 文件中获取
import { name } from './modules/bar.js';
console.log(name);
// bar中修改, main中验证
setTimeout(() => {
console.log(name);
}, 2000);但是,下面的代码是不成立的:main.js 中修改
import { name } from './modules/bar.js';
console.log(name);
// main中修改, bar中验证
setTimeout(() => {
name = 'kobe';
}, 1000);导入的变量不可以被修改

思考:如果 bar.js 中导出的是一个对象,那么 main.js 中是否可以修改对象中的属性呢?
- 答案是可以的,因为他们指向同一块内存空间;(自己编写代码验证,这里不再给出)
Node 中支持 ES Module
在 Current 版本中
在最新的 Current 版本(v14.13.1)中,支持 es module 我们需要进行如下操作:
- 方式一:在 package.json 中配置
type: module(后续再学习,我们现在还没有讲到 package.json 文件的作用) - 方式二:文件以
.mjs结尾,表示使用的是 ES Module;
这里我们暂时选择以 .mjs 结尾的方式来演练:
bar.mjs
const name = 'coderwhy';
export {
name
}main.mjs
import { name } from './modules/bar.mjs';
console.log(name);在 LTS 版本中
在最新的 LST 版本(v12.19.0)中,我们也是可以正常运行的,但是会报一个警告:
lts 版本的警告

ES Module 和 CommonJS 的交互
CommonJS 加载 ES Module
结论:通常情况下,CommonJS 不能加载 ES Module
- 因为 CommonJS 是同步加载的,但是 ES Module 必须经过静态分析等,无法在这个时候执行 JavaScript 代码;
- 但是这个并非绝对的,某些平台在实现的时候可以对代码进行针对性的解析,也可能会支持;
- Node 当中是不支持的;
ES Module 加载 CommonJS
结论:多数情况下,ES Module 可以加载 CommonJS
- ES Module 在加载 CommonJS 时,会将其 module.exports 导出的内容作为 default 导出方式来使用;
- 这个依然需要看具体的实现,比如 webpack 中是支持的、Node 最新的 Current 版本也是支持的;
- 但是在最新的 LTS 版本中就不支持;
| 321 | 3213 | 3123 |
|---|---|---|
| 133 | 313 this is a test | 313 |
| 313 | 313 | 313 |
| 312 | 131 | 313 |
foo.js
const address = 'foo的address';
module.exports = {
address
}main.js
import foo from './modules/foo.js';
console.log(foo.address);包管理工具【
概述【
package.json【
package-lock.json【
版本管理【
npm
认识 npm
我们已经学习了在 JavaScript 中可以通过模块化的方式将代码划分成一个个小的结构:
- 在以后的开发中我们就可以通过模块化的方式来封装自己的代码,并且封装成一个工具;
- 这个工具我们可以让同事通过导入的方式来使用,甚至你可以分享给世界各地的程序员来使用;
如果我们分享给世界上所有的程序员使用,有哪些方式呢?
方式一:上传到 GitHub 上、其他程序员通过 GitHub 下载我们的代码手动的引用;
- 缺点是大家必须知道你的代码 GitHub 的地址,并且从 GitHub 上手动下载;
- 需要在自己的项目中手动的引用,并且管理相关的依赖;
- 不需要使用的时候,需要手动来删除相关的依赖;
- 当遇到版本升级或者切换时,需要重复上面的操作;
显然,上面的方式是有效的,但是这种传统的方式非常麻烦,并且容易出错;
方式二:使用一个专业的工具来管理我们的代码
- 我们通过工具将代码发布到特定的位置;
- 其他程序员直接通过工具来安装、升级、删除我们的工具代码;
显然,通过第二种方式我们可以更好的管理自己的工具包,其他人也可以更好的使用我们的工具包。
包管理工具 npm:
- Node Package Manager,也就是 Node 包管理器;
- 但是目前已经不仅仅是 Node 包管理器了,在前端项目中我们也在使用它来管理依赖的包;
- 比如 express、koa、react、react-dom、axios、babel、webpack 等等;
npm 管理的包可以在哪里查看、搜索呢?
- https://www.npmjs.com/
- 这是我们安装相关的 npm 包的官网;
npm 管理的包存放在哪里呢?
- 我们发布自己的包其实是发布到 registry 上面的;
- 当我们安装一个包时其实是从 registry 上面下载的包;
项目配置文件
事实上,我们每一个项目都会有一个对应的配置文件,无论是前端项目还是后端项目:
- 这个配置文件会记录着你项目的名称、版本号、项目描述等;
- 也会记录着你项目所依赖的其他库的信息和依赖库的版本号;
这个配置文件在 Node 环境下面(无论是前端还是后端)就是 package.json。
我们以 vue cli4 脚手架创建的项目为例:
{
"name": "my-vue",
"version": "0.1.0",
"private": true,
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint"
},
"dependencies": {
"core-js": "^3.6.5",
"vue": "^2.6.11"
},
"devDependencies": {
"@vue/cli-plugin-babel": "~4.5.0",
"@vue/cli-plugin-eslint": "~4.5.0",
"@vue/cli-service": "~4.5.0",
"babel-eslint": "^10.1.0",
"eslint": "^6.7.2",
"eslint-plugin-vue": "^6.2.2",
"vue-template-compiler": "^2.6.11"
},
"browserslist": ["> 1%", "last 2 versions", "not dead"]
}事实上 Vue ClI4 脚手架创建的项目相对进行了简化,我们来看一下 CLI2 创建的项目:
{
"name": "vuerouterbasic",
"version": "1.0.0",
"description": "A Vue.js project",
"author": "'coderwhy' <'coderwhy@gmail.com'>",
"private": true,
"scripts": {
"dev": "webpack-dev-server --inline --progress --config build/webpack.dev.conf.js",
"start": "npm run dev",
"build": "node build/build.js"
},
"dependencies": {
"vue": "^2.5.2",
"vue-router": "^3.0.1"
},
"devDependencies": {
"autoprefixer": "^7.1.2",
"babel-core": "^6.22.1",
"babel-helper-vue-jsx-merge-props": "^2.0.3",
"babel-loader": "^7.1.1",
"babel-plugin-syntax-jsx": "^6.18.0",
"babel-plugin-transform-runtime": "^6.22.0",
"babel-plugin-transform-vue-jsx": "^3.5.0",
"babel-preset-env": "^1.3.2",
"babel-preset-stage-2": "^6.22.0",
"chalk": "^2.0.1",
"copy-webpack-plugin": "^4.0.1",
"css-loader": "^0.28.0",
"extract-text-webpack-plugin": "^3.0.0",
"file-loader": "^1.1.4",
"friendly-errors-webpack-plugin": "^1.6.1",
"html-webpack-plugin": "^2.30.1",
"node-notifier": "^5.1.2",
"optimize-css-assets-webpack-plugin": "^3.2.0",
"ora": "^1.2.0",
"portfinder": "^1.0.13",
"postcss-import": "^11.0.0",
"postcss-loader": "^2.0.8",
"postcss-url": "^7.2.1",
"rimraf": "^2.6.0",
"semver": "^5.3.0",
"shelljs": "^0.7.6",
"uglifyjs-webpack-plugin": "^1.1.1",
"url-loader": "^0.5.8",
"vue-loader": "^13.3.0",
"vue-style-loader": "^3.0.1",
"vue-template-compiler": "^2.5.2",
"webpack": "^3.6.0",
"webpack-bundle-analyzer": "^2.9.0",
"webpack-dev-server": "^2.9.1",
"webpack-merge": "^4.1.0"
},
"engines": {
"node": ">= 6.0.0",
"npm": ">= 3.0.0"
},
"browserslist": ["> 1%", "last 2 versions", "not ie <= 8"]
}我们也可以手动创建一个 package.json 文件:
npm init # 创建时填写信息
npm init -y # 所有信息使用默认的npm init -y生成文件的效果:
{
"name": "learn-npm",
"version": "1.0.0",
"description": "",
"main": "main.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}我们会发现属性非常的多,我们这里对一些常见属性进行一些解析。
必须填写的属性:name、version
- name 是项目的名称;
- version 是当前项目的版本号;
- description 是描述信息,很多时候是作为项目的基本描述;
- author 是作者相关信息(发布时用到);
- license 是开源协议(发布时用到);
private 属性:
- private 属性记录当前的项目是否是私有的;
- 当值为 true 时,npm 是不能发布它的,这是防止私有项目或模块发布出去的方式;
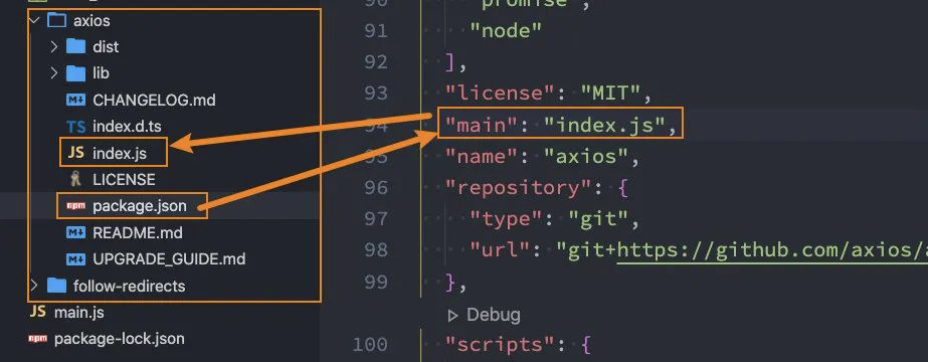
main 属性:
设置程序的入口。
很多人会有疑惑,webpack 不是会自动找到程序的入口吗?
- 这个入口和 webpack 打包的入口并不冲突;
- 它是在你发布一个模块的时候会用到的;
- 比如我们使用 axios 模块
const axios = require('axios'); - 实际上是找到对应的 main 属性查找文件的;
axios 的入口
scripts 属性
scripts 属性用于配置一些脚本命令,以键值对的形式存在;
配置后我们可以通过
npm run 命令的key来执行这个命令;npm start和npm run start的区别是什么?- 它们是等价的;
- 对于常用的 start、 test、stop、restart 可以省略掉 run 直接通过
npm start等方式运行;
dependencies 属性
- dependencies 属性是指定无论开发环境还是生成环境都需要依赖的包;
- 通常是我们项目实际开发用到的一些库模块;
- 与之对应的是 devDependencies;
devDependencies 属性
- 一些包在生成环境是不需要的,比如 webpack、babel 等;
- 这个时候我们会通过
npm install webpack --save-dev,将它安装到 devDependencies 属性中;
疑问:那么在生成环境如何保证不安装这些包呢?
- 生成环境不需要安装时,我们需要通过
npm install --production来安装文件的依赖;
版本管理的问题
我们会发现安装的依赖版本出现:^2.0.3或~2.0.3,这是什么意思呢?
npm 的包通常需要遵从 semver 版本规范:
- semver:https://semver.org/lang/zh-CN/
- npm semver:https://docs.npmjs.com/misc/semver
semver 版本规范是 X.Y.Z:
- X 主版本号(major):当你做了不兼容的 API 修改(可能不兼容之前的版本);
- Y 次版本号(minor):当你做了向下兼容的功能性新增(新功能增加,但是兼容之前的版本);
- Z 修订号(patch):当你做了向下兼容的问题修正(没有新功能,修复了之前版本的 bug);
我们这里解释一下 ^和~的区别:
^x.y.z:表示 x 是保持不变的,y 和 z 永远安装最新的版本;~x.y.z:表示 x 和 y 保持不变的,z 永远安装最新的版本;
engines 属性
- engines 属性用于指定 Node 和 NPM 的版本号;
- 在安装的过程中,会先检查对应的引擎版本,如果不符合就会报错;
- 事实上也可以指定所在的操作系统
"os" : [ "darwin", "linux" ],只是很少用到;
browserslist 属性
- 用于配置打包后的 JavaScript 浏览器的兼容情况,参考;
- 否则我们需要手动的添加 polyfills 来让支持某些语法;
- 也就是说它是为 webpack 等打包工具服务的一个属性(这里不是详细讲解 webpack 等工具的工作原理,所以不再给出详情);
npm 工具解析
npm install 命令
安装 npm 包分两种情况:
- 全局安装(global install):
npm install yarn -g; - 项目(局部)安装(local install):
npm install
全局安装
全局安装是直接将某个包安装到全局:
比如 yarn 的全局安装:
npm install yarn -g但是很多人对全局安装有一些误会:
- 通常使用 npm 全局安装的包都是一些工具包:yarn、webpack 等;
- 并不是类似于 axios、express、koa 等库文件;
- 所以全局安装了之后并不能让我们在所有的项目中使用 axios 等库;
项目安装
项目安装会在当前目录下生产一个 node_modules 文件夹,我们之前讲解 require 查找顺序时有讲解过这个包在什么情况下被查找;
局部安装分为开发时依赖和生产时依赖:
# 安装开发和生产依赖
npm install axios --save
npm install axios -S
npm install axios
npm i axios
# 开发者
npm install axios --save-dev
npm install axios -D
npm i axios -Dnpm install 原理
很多同学之情应该已经会了 npm install <package>,但是你是否思考过它的内部原理呢?
- 执行
npm install它背后帮助我们完成了什么操作? - 我们会发现还有一个成为 package-lock.json 的文件,它的作用是什么?
- 从 npm5 开始,npm 支持缓存策略(来自 yarn 的压力),缓存有什么作用呢?
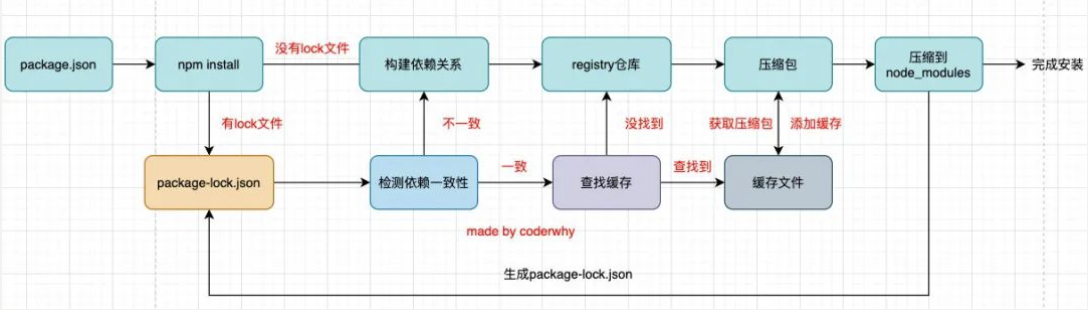
这是一幅我画出的根据 npm install 的原理图:
npm install 会检测是有 package-lock.json 文件:
- 检测 lock 中包的版本是否和 package.json 中一致(会按照 semver 版本规范检测);
- 一致的情况下,会去优先查找缓存
- 查找到,会获取缓存中的压缩文件,并且将压缩文件解压到 node_modules 文件夹中;
- 不一致,那么会重新构建依赖关系,直接会走顶层的流程;
- 没有找到,会从 registry 仓库下载,直接走顶层流程;
- 分析依赖关系,这是因为我们可能包会依赖其他的包,并且多个包之间会产生相同依赖的情况;
- 从 registry 仓库中下载压缩包(如果我们设置了镜像,那么会从镜像服务器下载压缩包);
- 获取到压缩包后会对压缩包进行缓存(从 npm5 开始有的);
- 将压缩包解压到项目的 node_modules 文件夹中(前面我们讲过,require 的查找顺序会在该包下面查找)
- 没有 lock 文件
- 有 lock 文件
npm install 原理图
package-lock.json 文件:
{
"name": "learn-npm",
"version": "1.0.0",
"lockfileVersion": 1,
"requires": true,
"dependencies": {
"axios": {
"version": "0.20.0",
"resolved": "https://registry.npmjs.org/axios/-/axios-0.20.0.tgz",
"integrity": "sha512-ANA4rr2BDcmmAQLOKft2fufrtuvlqR+cXNNinUmvfeSNCOF98PZL+7M/v1zIdGo7OLjEA9J2gXJL+j4zGsl0bA==",
"requires": {
"follow-redirects": "^1.10.0"
}
},
"follow-redirects": {
"version": "1.13.0",
"resolved": "https://registry.npmjs.org/follow-redirects/-/follow-redirects-1.13.0.tgz",
"integrity": "sha512-aq6gF1BEKje4a9i9+5jimNFIpq4Q1WiwBToeRK5NvZBd/TRsmW8BsJfOEGkr76TbOyPVD3OVDN910EcUNtRYEA=="
}
}
}package-lock.json 文件解析:
name:项目的名称;
version:项目的版本;
lockfileVersion:lock 文件的版本;
requires:使用 requires 来跟着模块的依赖关系;
dependencies:项目的依赖
- version 表示实际安装的 axios 的版本;
- resolved 用来记录下载的地址,registry 仓库中的位置;
- requires 记录当前模块的依赖;
- integrity 用来从缓存中获取索引,再通过索引去获取压缩包文件;
- 当前项目依赖 axios,但是 axios 依赖 follow-redireacts;
- axios 中的属性如下:
其他 npm 命令
我们这里再介绍几个比较常用的:
卸载某个依赖包:
npm uninstall package
npm uninstall package --save-dev
npm uninstall package -D强制重新 build
npm rebuild清除缓存
npm cache cleannpm 的命令其实是非常多的:
- https://docs.npmjs.com/cli-documentation/cli
- 更多的命令,可以根据需要查阅官方文档
npx
npx 是 npm5.2 之后自带的一个命令。
npx 的作用非常多,但是比较常见的是使用它来调用项目中的某个模块的指令。
我们以 webpack 为例:
- 全局安装的是 webpack5.1.3
- 项目安装的是 webpack3.6.0
如果我在终端执行 webpack --version使用的是哪一个命令呢?
- 显示结果会是
webpack 5.1.3,事实上使用的是全局的,为什么呢? - 原因非常简单,在当前目录下找不到 webpack 时,就会去全局找,并且执行命令;
那么如何使用项目(局部)的 webpack,常见的是两种方式:
- 方式一:明确查找到 node_module 下面的 webpack
- 方式二:在
scripts定义脚本,来执行 webpack;
方式一:在终端中使用如下命令(在项目根目录下)
./node_modules/.bin/webpack --version方式二:修改 package.json 中的 scripts
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"webpack": "webpack --version"
},终端中执行:
npm run webpack但是这两种方式都有一点点麻烦,更好的办法是直接使用 npx:
npx webpack --versionnpx 的原理非常简单,它会到当前目录的 node_modules/.bin 目录下查找对应的命令;
yarn
另一个 node 包管理工具 yarn:
- yarn 是由 Facebook、Google、Exponent 和 Tilde 联合推出了一个新的 JS 包管理工具;
- yarn 是为了弥补 npm 的一些缺陷而出现的;
- 早期的 npm 存在很多的缺陷,比如安装依赖速度很慢、版本依赖混乱等等一系列的问题;
- 虽然从 npm5 版本开始,进行了很多的升级和改进,但是依然很多人喜欢使用 yarn;
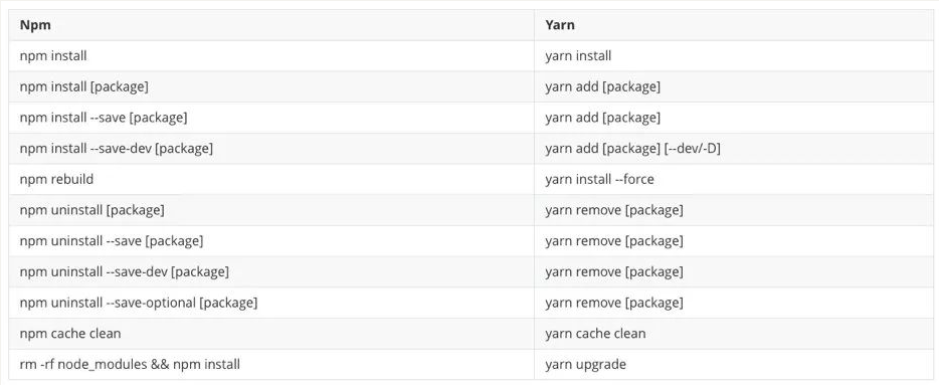
这里给出一张常用命令的对比
cnpm
由于一些特殊的原因,某些情况下我们没办法很好的从 https://registry.npmjs.org下载下来一些需要的包。
查看 npm 镜像:
npm config get registry # npm config get registry我们可以直接设置 npm 的镜像:
npm config set registry https://registry.npm.taobao.org但是对于大多数人来说(比如我),并不希望将 npm 镜像修改了:
- 第一,不太希望随意修改 npm 原本从官方下来包的渠道;
- 第二,担心某天淘宝的镜像挂了或者不维护了,又要改来改去;
这个时候,我们可以使用 cnpm,并且将 cnpm 设置为淘宝的镜像:
npm install -g cnpm --registry=https://registry.npm.taobao.org
cnpm config get registry # https://r.npm.taobao.org/pnpm【
monorepo
发布包【
事件循环
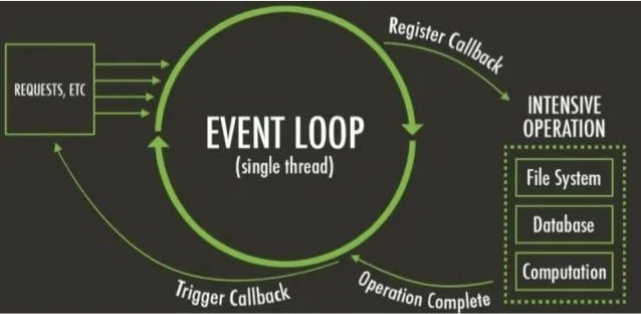
事件循环是什么?事实上我把事件循环理解成我们编写的 JavaScript 和浏览器或者 Node 之间的一个桥梁。
浏览器的事件循环是一个我们编写的 JavaScript 代码和浏览器 API 调用(setTimeout/AJAX/监听事件等)的一个桥梁, 桥梁之间他们通过回调函数进行沟通。
Node 的事件循环是一个我们编写的 JavaScript 代码和系统调用(file system、network 等)之间的一个桥梁, 桥梁之间他们通过回调函数进行沟通的.
浏览器事件循环
进程和线程
线程和进程是操作系统中的两个概念:
- 进程(process):计算机已经运行的程序;
- 线程(thread):操作系统能够运行运算调度的最小单位;
听起来很抽象,我们直观一点解释:
- 进程:我们可以认为,启动一个应用程序,就会默认启动一个进程(也可能是多个进程);
- 线程:每一个进程中,都会启动一个线程用来执行程序中的代码,这个线程被称之为主线程;
- 所以我们也可以说进程是线程的容器;
再用一个形象的例子解释:
- 操作系统类似于一个工厂;
- 工厂中里有很多车间,这个车间就是进程;
- 每个车间可能有一个以上的工人在工厂,这个工人就是线程;
操作系统、线程、进程
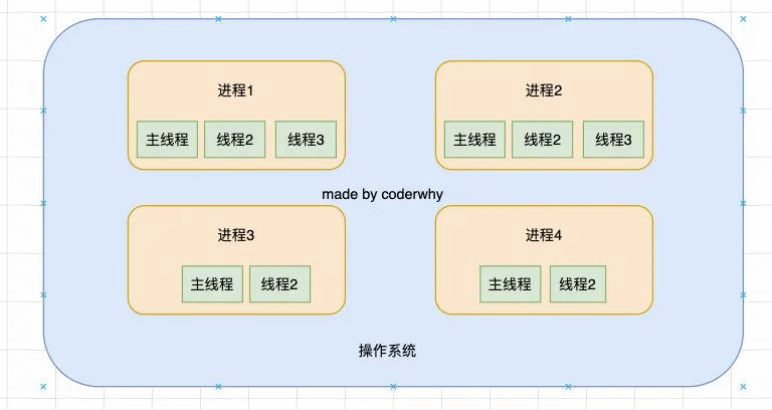
操作系统是如何做到同时让多个进程(边听歌、边写代码、边查阅资料)同时工作呢?
- 这是因为 CPU 的运算速度非常快,它可以快速的在多个进程之间迅速的切换;
- 当我们的进程中的线程获取获取到时间片时,就可以快速执行我们编写的代码;
- 对于用于来说是感受不到这种快速的切换的;
你可以在 Mac 的活动监视器或者 Windows 的资源管理器中查看到很多进程:
活动监视器
浏览器和 JavaScript
我们经常会说 JavaScript 是单线程的,但是 JavaScript 的线程应该有自己的容器进程:浏览器或者 Node。
浏览器是一个进程吗,它里面只有一个线程吗?
- 目前多数的浏览器其实都是多进程的,当我们打开一个 tab 页面时就会开启一个新的进程,这是为了防止一个页面卡死而造成所有页面无法响应,整个浏览器需要强制退出;
- 每个进程中又有很多的线程,其中包括执行 JavaScript 代码的线程;
但是 JavaScript 的代码执行是在一个单独的线程中执行的:
- 这就意味着 JavaScript 的代码,在同一个时刻只能做一件事;
- 如果这件事是非常耗时的,就意味着当前的线程就会被阻塞;
分析下面代码的执行过程:
- 定义变量 name;
- 执行 log 函数,函数会被放入到调用栈中执行;
- 调用 bar()函数,被压入到调用栈中,但是执行未结束;
- bar 因为调用了 sum,sum 函数被压入到调用栈中,获取到结果后出栈;
- bar 获取到结果后出栈,获取到结果 result;
- 将 log 函数压入到调用栈,log 被执行,并且出栈;
const name = 'coderwhy'
// 1.将该函数放入到调用栈中被执行
console.log(name)
// 2. 调用栈
function sum(num1, num2) {
return num1 + num2
}
function bar() {
return sum(20, 30)
}
console.log(bar())浏览器的事件循环
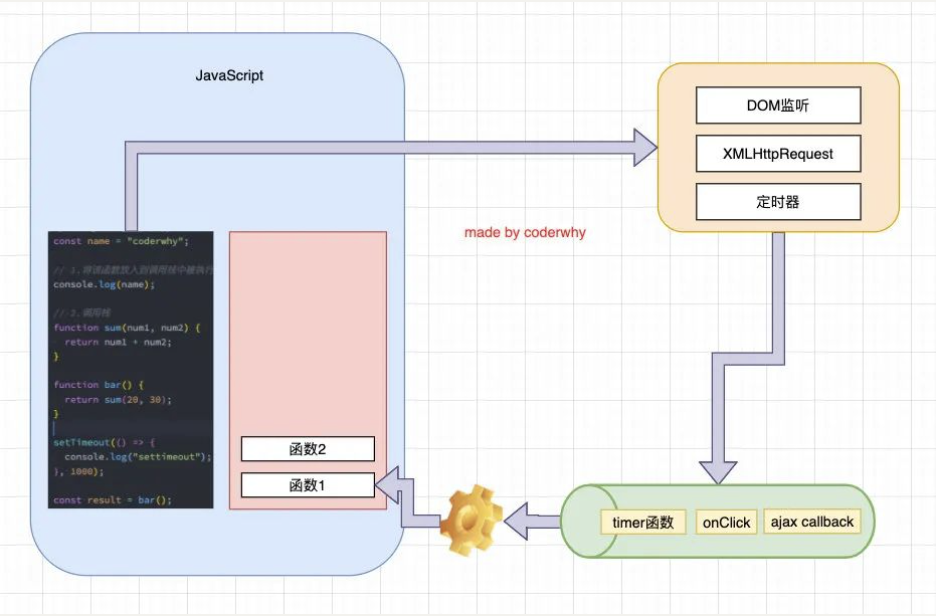
如果在执行 JavaScript 代码的过程中,有异步操作呢?
- 中间我们插入了一个 setTimeout 的函数调用;
- 这个函数被放到入调用栈中,执行会立即结束,并不会阻塞后续代码的执行;
const name = 'coderwhy'
// 1.将该函数放入到调用栈中被执行
console.log(name)
// 2.调用栈
function sum(num1, num2) {
return num1 + num2
}
function bar() {
return sum(20, 30)
}
setTimeout(() => {
console.log('settimeout')
}, 1000)
const result = bar()
console.log(result)那么,传入的一个函数(比如我们称之为 timer 函数),会在什么时候被执行呢?
- 事实上,setTimeout 是调用了 web api,在合适的时机,会将 timer 函数加入到一个事件队列中;
- 事件队列中的函数,会被放入到调用栈中,在调用栈中被执行;
浏览器的事件循环
宏任务和微任务
但是事件循环中并非只维护着一个队列,事实上是有两个队列:
- 宏任务队列(macrotask queue):ajax、setTimeout、setInterval、DOM 监听、UI Rendering 等
- 微任务队列(microtask queue):Promise 的 then 回调、 Mutation Observer API、queueMicrotask()等
那么事件循环对于两个队列的优先级是怎么样的呢?
1.main script 中的代码优先执行(编写的顶层 script 代码);
2.在执行任何一个宏任务之前(不是队列,是一个宏任务),都会先查看微任务队列中是否有任务需要执行
- 也就是宏任务执行之前,必须保证微任务队列是空的;
- 如果不为空,那么就优先执行微任务队列中的任务(回调);
我们来看一个面试题:执行结果如何?
setTimeout(function () {
console.log('set1')
new Promise(function (resolve) {
resolve()
}).then(function () {
new Promise(function (resolve) {
resolve()
}).then(function () {
console.log('then4')
})
console.log('then2')
})
})
new Promise(function (resolve) {
console.log('pr1')
resolve()
}).then(function () {
console.log('then1')
})
setTimeout(function () {
console.log('set2')
})
console.log(2)
queueMicrotask(() => {
console.log('queueMicrotask1')
})
new Promise(function (resolve) {
resolve()
}).then(function () {
console.log('then3')
})执行结果:
pr1
2
then1
queueMicrotask1
then3
set1
then2
then4
set2async、await 是 Promise 的一个语法糖:
- 我们可以将 await 关键字后面执行的代码,看做是包裹在
(resolve, reject) => {函数执行}中的代码; - await 的下一条语句,可以看做是
then(res => {函数执行})中的代码;
今日头条的面试题:
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
console.log('script start')
setTimeout(function () {
console.log('setTimeout')
}, 0)
async1()
new Promise(function (resolve) {
console.log('promise1')
resolve()
}).then(function () {
console.log('promise2')
})
console.log('script end')执行结果如下:
script start
async1 start
async2
promise1
script end
async1 end
promise2
setTimeoutNode 事件循环
Node 的事件循环
浏览器中的 EventLoop 是根据 HTML5 定义的规范来实现的,不同的浏览器可能会有不同的实现,而 Node 中是由 libuv 实现的。
我们来看在很早就给大家展示的 Node 架构图:
- 我们会发现 libuv 中主要维护了一个 EventLoop 和 worker threads(线程池);
- EventLoop 负责调用系统的一些其他操作:文件的 IO、Network、child-processes 等
Node 的架构图
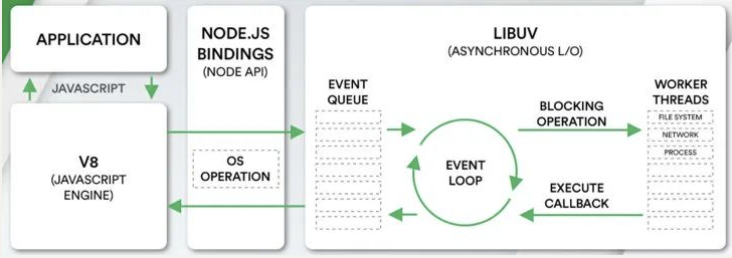
libuv 到底是什么呢?
- libuv is a multi-platform support library with a focus on asynchronous I/O. It was primarily developed for use by Node.js, but it's also used by Luvit, Julia, pyuv, and others.
- libuv 是一个多平台的专注于异步 IO 的库,它最初是为 Node 开发的,但是现在也被使用到 Luvit、Julia、pyuv 等其他地方;
libuv 到底帮助我们做了什么事情呢?
- 我们以文件操作为例,来讲解一下它内部的结构;
阻塞 IO 和非阻塞 IO
如果我们希望在程序中对一个文件进行操作,那么我们就需要打开这个文件:通过文件描述符。
- 我们思考:JavaScript 可以直接对一个文件进行操作吗?
- 看起来是可以的,但是事实上我们任何程序中的文件操作都是需要进行系统调用(操作系统封装了文件系统);
- 事实上对文件的操作,是一个操作系统的 IO 操作(输入、输出);
操作系统为我们提供了阻塞式调用和非阻塞式调用:
- 阻塞式调用: 调用结果返回之前,当前线程处于阻塞态(阻塞态 CPU 是不会分配时间片的),调用线程只有在得到调用结果之后才会继续执行。
- 非阻塞式调用: 调用执行之后,当前线程不会停止执行,只需要过一段时间来检查一下有没有结果返回即可。
所以我们开发中的很多耗时操作,都可以基于这样的 非阻塞式调用:
- 比如网络请求本身使用了 Socket 通信,而 Socket 本身提供了 select 模型,可以进行
非阻塞方式的工作; - 比如文件读写的 IO 操作,我们可以使用操作系统提供的
基于事件的回调机制;
但是非阻塞 IO 也会存在一定的问题:我们并没有获取到需要读取(我们以读取为例)的结果
- 那么就意味着为了可以知道是否读取到了完整的数据,我们需要频繁的去确定读取到的数据是否是完整的;
- 这个过程我们称之为轮训操作;
那么这个轮训的工作由谁来完成呢?
- 如果我们的主线程频繁的去进行轮训的工作,那么必然会大大降低性能;
- 并且开发中我们可能不只是一个文件的读写,可能是多个文件;
- 而且可能是多个功能:网络的 IO、数据库的 IO、子进程调用;
libuv 提供了一个线程池(Thread Pool):
- 线程池会负责所有相关的操作,并且会通过轮训等方式等待结果;
- 当获取到结果时,就可以将对应的回调放到事件循环(某一个事件队列)中;
- 事件循环就可以负责接管后续的回调工作,告知 JavaScript 应用程序执行对应的回调函数;
Event loop in node.js
阻塞和非阻塞,同步和异步有什么区别?
阻塞和非阻塞是对于被调用者来说的;
- 在我们这里就是系统调用,操作系统为我们提供了阻塞调用和非阻塞调用;
同步和异步是对于调用者来说的;
- 在我们这里就是自己的程序;
- 如果我们在发起调用之后,不会进行其他任何的操作,只是等待结果,这个过程就称之为同步调用;
- 如果我们再发起调用之后,并不会等待结果,继续完成其他的工作,等到有回调时再去执行,这个过程就是异步调用;
Node 事件循环的阶段
我们最前面就强调过,事件循环像是一个桥梁,是连接着应用程序的 JavaScript 和系统调用之间的通道:
- 无论是我们的文件 IO、数据库、网络 IO、定时器、子进程,在完成对应的操作后,都会将对应的结果和回调函数放到事件循环(任务队列)中;
- 事件循环会不断的从任务队列中取出对应的事件(回调函数)来执行;
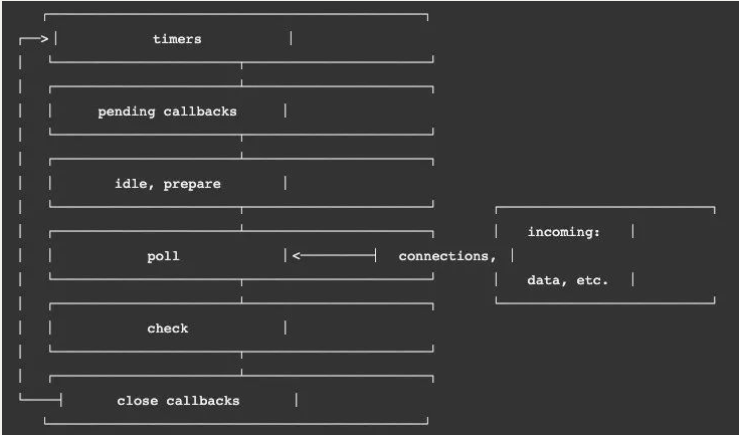
但是一次完整的事件循环 Tick 分成很多个阶段:
- 定时器(Timers):本阶段执行已经被
setTimeout()和setInterval()的调度回调函数。 - 待定回调(Pending Callback):对某些系统操作(如 TCP 错误类型)执行回调,比如 TCP 连接时接收到 ECONNREFUSED。
- idle, prepare:仅系统内部使用。
- 轮询(Poll):检索新的 I/O 事件;执行与 I/O 相关的回调;
- 检测:
setImmediate()回调函数在这里执行。 - 关闭的回调函数:一些关闭的回调函数,如:
socket.on('close', ...)。
一次 tick 的事件循环阶段
我们会发现从一次事件循环的 Tick 来说,Node 的事件循环更复杂,它也分为微任务和宏任务:
- 宏任务(macrotask):setTimeout、setInterval、IO 事件、setImmediate、close 事件;
- 微任务(microtask):Promise 的 then 回调、process.nextTick、queueMicrotask;
但是,Node 中的事件循环不只是 微任务队列和 宏任务队列:
微任务队列:
- next tick queue:process.nextTick;
- other queue:Promise 的 then 回调、queueMicrotask;
宏任务队列:
- timer queue:setTimeout、setInterval;
- poll queue:IO 事件;
- check queue:setImmediate;
- close queue:close 事件;
所以,在每一次事件循环的 tick 中,会按照如下顺序来执行代码:
- next tick microtask queue;
- other microtask queue;
- timer queue;
- poll queue;
- check queue;
- close queue;
Node 代码执行面试
面试题一:
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
console.log('script start')
setTimeout(function () {
console.log('setTimeout0')
}, 0)
setTimeout(function () {
console.log('setTimeout2')
}, 300)
setImmediate(() => console.log('setImmediate'))
process.nextTick(() => console.log('nextTick1'))
async1()
process.nextTick(() => console.log('nextTick2'))
new Promise(function (resolve) {
console.log('promise1')
resolve()
console.log('promise2')
}).then(function () {
console.log('promise3')
})
console.log('script end')执行结果如下:
script start
async1 start
async2
promise1
promise2
script end
nextTick
async1 end
promise3
setTimeout0
setImmediate
setTimeout2面试题二:
setTimeout(() => {
console.log('setTimeout')
}, 0)
setImmediate(() => {
console.log('setImmediate')
})执行结果:
情况一:
setTimeout
setImmediate
情况二:
setImmediate
setTimeout为什么会出现不同的情况呢?
- 在 Node 源码的 deps/uv/src/timer.c 中 141 行,有一个
uv__next_timeout的函数; - 这个函数决定了,poll 阶段要不要阻塞在这里;
- 阻塞在这里的目的是当有异步 IO 被处理时,尽可能快的让代码被执行;
int uv__next_timeout(const uv_loop_t* loop) {
const struct heap_node* heap_node;
const uv_timer_t* handle;
uint64_t diff;
// 计算距离当前时间节点最小的计时器
heap_node = heap_min(timer_heap(loop));
// 如果为空, 那么返回-1,表示为阻塞状态
if (heap_node == NULL)
return -1; /* block indefinitely */
// 如果计时器的时间小于当前loop的开始时间, 那么返回0
// 继续执行后续阶段, 并且开启下一次tick
handle = container_of(heap_node, uv_timer_t, heap_node);
if (handle->timeout <= loop->time)
return 0;
// 如果不大于loop的开始时间, 那么会返回时间差
diff = handle->timeout - loop->time;
if (diff > INT_MAX)
diff = INT_MAX;
return (int) diff;
}和上面有什么关系呢?
情况一:如果事件循环开启的时间(ms)是小于
setTimeout函数的执行时间的;- 也就意味着先开启了 event-loop,但是这个时候执行到 timer 阶段,并没有定时器的回调被放到入 timer queue 中;
- 所以没有被执行,后续开启定时器和检测到有 setImmediate 时,就会跳过 poll 阶段,向后继续执行;
- 这个时候是先检测
setImmediate,第二次的 tick 中执行了 timer 中的setTimeout;
情况二:如果事件循环开启的时间(ms)是大于
setTimeout函数的执行时间的;- 这就意味着在第一次 tick 中,已经准备好了 timer queue;
- 所以会直接按照顺序执行即可;